Elasticsearch 入门
二月其二,入门 Elasticsearch。
本文主要在写 Elasticsearch 是什么,捎带着写一点 Elasticsearch 怎么用。
Elasticsearch(简称 ES)是一款全文搜索引擎。
全文搜索(full-text search)的意思是从一大段文字中找出指定内容,比如从 100 篇文章中找出哪几篇包含“Hello world!”这句话,再比如百度、谷歌等搜索引擎也是。
Elasticsearch 有非常多的特点,下面罗列一些:
分布式
在多台机器上启动多个 Elasticsearch 进程实例,组成一个集群,可以扩展到上百台服务器,处理 PB 级数据。
基于分布式,同时能够保证高可用(部分节点挂了,集群依然正常服务)和高伸缩性(副本分片数动态调整,提高读性能)。
近实时查询(near real-time search)
写数据后不能立即查到,过一段时间才能查到,默认 1 秒。
基于 Lucene
Lucene(音 [ˈluːsin])是一套开源的全文搜索程序库,基于 Java 编写,可以看做一个第三方 Java 库,使用起来不太方便。
Elasticsearch 基于 Lucene 实现,并且做到高可用、分布式,它的每个分片都是一个功能齐全的 Lucene 索引。
REST APIs
Elasticsearch 使用 RESTful 接口,例如查询
students索引中id=1的记录:1
GET students/_doc/1
Elasticsearch 很喜欢自称使用 REST APIs,应该是因为 Lucene 用起来太复杂了。
Elastic Stack 的一部分
Elasticsearch 的母公司是 Elastic,它们的核心产品是 Elastic Stack,一个由多个开源软件组成的软件栈:
- Elasticsearch
- Logstash(用于采集数据)
- Kibana(用于数据可视化)
- Beats(用于采集数据,轻量级+只采集日志)
最开始只有 Elasticsearch、Logstash、Kibana,统称为 ELK,后来加入 Beats 后更名为 Elastic Stack。
Elasticsearch 历史
梳理一下 Elasticsearch 的历史。
Elasticsearch 的前身是 Compass,由 Shay Banon 在 2004 年开发,后来为了分布式和可扩展性,作者重写了一遍,命名 Elasticsearch(最初版本是 0.x),在 2014 年发布了 Elasticsearch 1.0。
2015 年 Elasticsearch 发布 2.0,官网上的中文教程《Elasticsearch: 权威指南》就是基于这个版本(其他版本乖乖看英文)。
Elasticsearch 为了和 Kibana 和 Logstash 统一版本号,没有 3.x 和 4.x,而直接是 5.x 版本。
前不久 Elasticsearch 刚刚发布 8.0,更新主要关于安全和机器学习:《Elastic 8.0: A new era of speed, scale, relevance, and simplicity》。
Elastic 官网上有相关发展史,可以一读:《发展历程》。
分享一个无用小知识:Elasticsearch 的前身 Compass,是作者失业后陪老婆去英国学厨,给老婆管理菜谱用的。
再分享一个无用小知识:Elasticsearch 的基础 Lucene,这个词没啥意思,是作者老婆的中间名。
启动 Elasticsearch
所有 Elasticsearch 的学习文档,上来都是教怎么安装 Elasticsearch 和 Kibana,洋洋洒洒一大篇。(因为 Elasticsearch 的操作界面是在 Kibana 上的,因此一般都同时安装 Kibana 并启动)
分享另一个官方思路(具体可以参考《Quick start》),使用 Docker 运行 Elasticsearch 和 Kibana,这样简单快速。
安装 Docker 并启动
执行下面的语句
1
2
3
4
5
6
7# 拉取 Elasticsearch 镜像并启动
docker network create elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.0.0
docker run --name es-node01 --net elastic -p 9200:9200 -p 9300:9300 -it docker.elastic.co/elasticsearch/elasticsearch:8.0.0
# 拉取 Kibana 镜像并启动
docker pull docker.elastic.co/kibana/kibana:8.0.0
docker run --name kib-01 --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.0.0打开 Kibana 控制台:http://localhost:5601/app/dev_tools#/console
控制台默认就会有一个查询语句,用于查询所有数据。
也可以在 Kibana 上通过点击找到控制台:http://localhost:5601/ -> 左侧菜单栏 -> Management -> DevTools -> Console
然后就可以在 Kibana 控制台上操作 Elasticsearch 了。
基本概念
Elasticsearch 基础概念可以分为两部分,一部分关于数据库,一部分关于分布式。
数据库相关
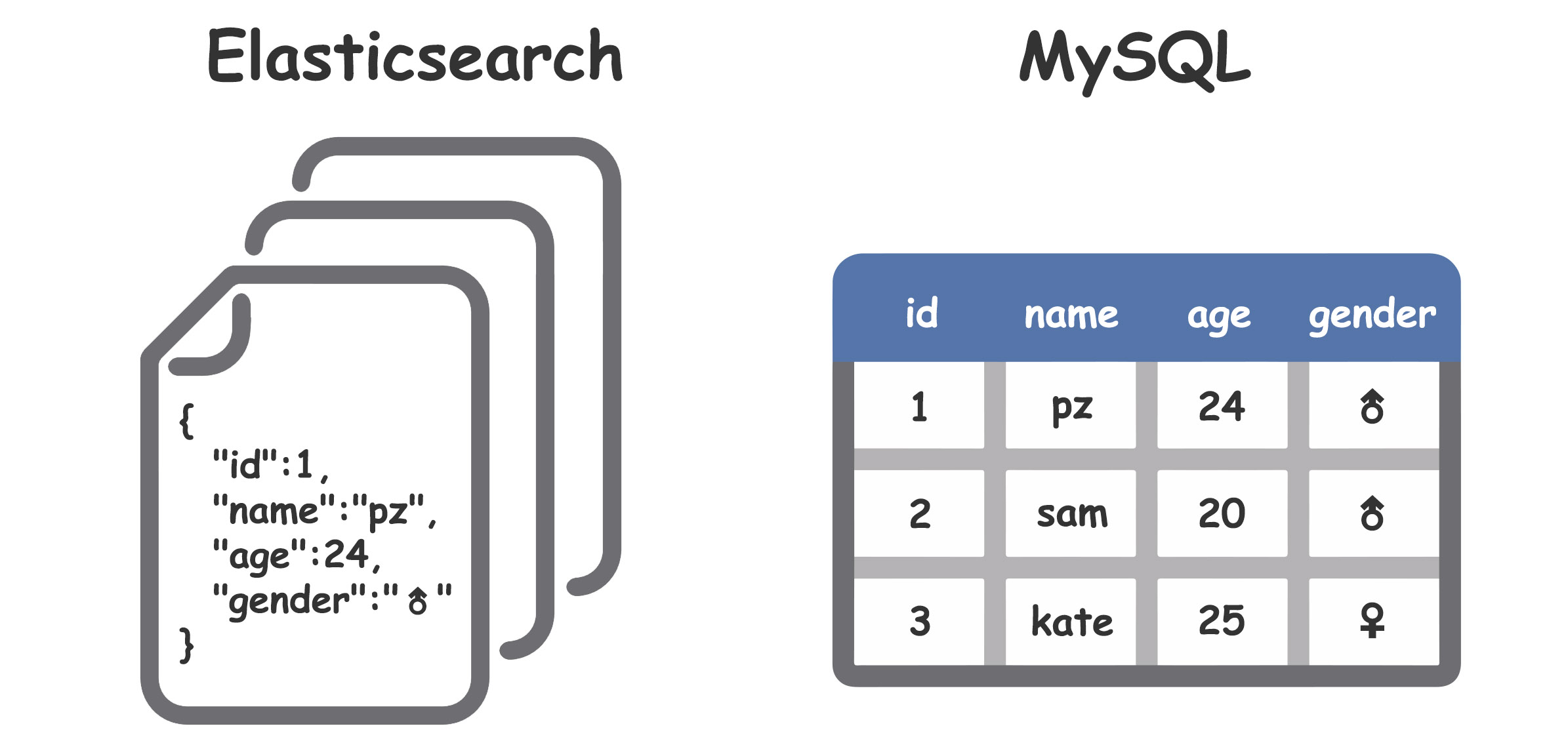
如果简单地看待 Elasticsearch,它就是一个数据库(就像是 MySQL、MongoDB),同样有 表(Table)、数据行(Row)、查询语法(SQL) 等类似概念(但是术语不同)。
整理一下 Elasticsearch 与关系型数据库的术语对应关系:
| 关系型数据库 - 术语 | Elasticsearch - 术语 | Elasticsearch - 术语中文翻译 | 备注 |
|---|---|---|---|
| Database | Index | 索引 | Index 复数是 Indices |
| Table | Type | 类型 | 已废弃 6.0 开始,每个 Index 只能有一个 Type 8.0 开始,废弃使用 Type(每个 Index 只有一个默认不可改的 Type: _doc) |
| Row | Document | 文档 | 以 JSON 格式表示 |
| Column | Field | 字段 | |
| Schema | Mapping | 映射/关联 | 可以不需要有建表这个行为 插入一条数据,将自动创建 Index、Field 并进行 mapping |
| SQL | Query DSL | 查询表达式,DSL (Domain Specific Language) |
需要单独提一下 Elasticsearch 表的概念。
如果把 Elasticsearch 和 MySQL 做类比,一个数据库内包含多张表,一张表内有多条数据,关系应该是这样的:
- MySQL => Databases => Tables => Columns/Rows
- Elasticsearch => Indices => Types => Documents with Properties
但是,Elasticsearch 中的数据(Document)实际上是直接存储在数据库(Index)下的,表(Type)只是一个逻辑概念。
具体来讲:在 MySQL 中,不同 Table 下的 Column 是相互独立、没啥关系的(比如员工表和项目表,都可以有 name 字段 ),但是在 Elasticsearch 中,同一个 Index 下不可以有同名字段,即使是不一样的 Type,也不可以有重名的字段,Type 只是逻辑概念,字段是共用的。
Elasticsearch 8.0 开始正式废弃 Type。
我觉得 Elasticsearch 和 MySQL 等传统关系型数据库相比,有两个主要不同:
Elasticsearch 是面向文档的 NoSQL 数据库(类似 MongoDB)。
Elasticsearch 可以全文搜索(当然前提是高性能)。
例如查询包含
error一词的日志,SQL 语句类似如下(MySQL 肯定特别慢):1
SELECT * FROM t_log WHERE content LIKE "%error%"
推荐阅读官方文档:《Data in: documents and indices》。
分布式相关
Elasticsearch 是一个分布式搜索引擎,通过在多台机器上启动 Elasticsearch 实例,组成一个 Elasticsearch 集群,实现高可用性和高伸缩性。
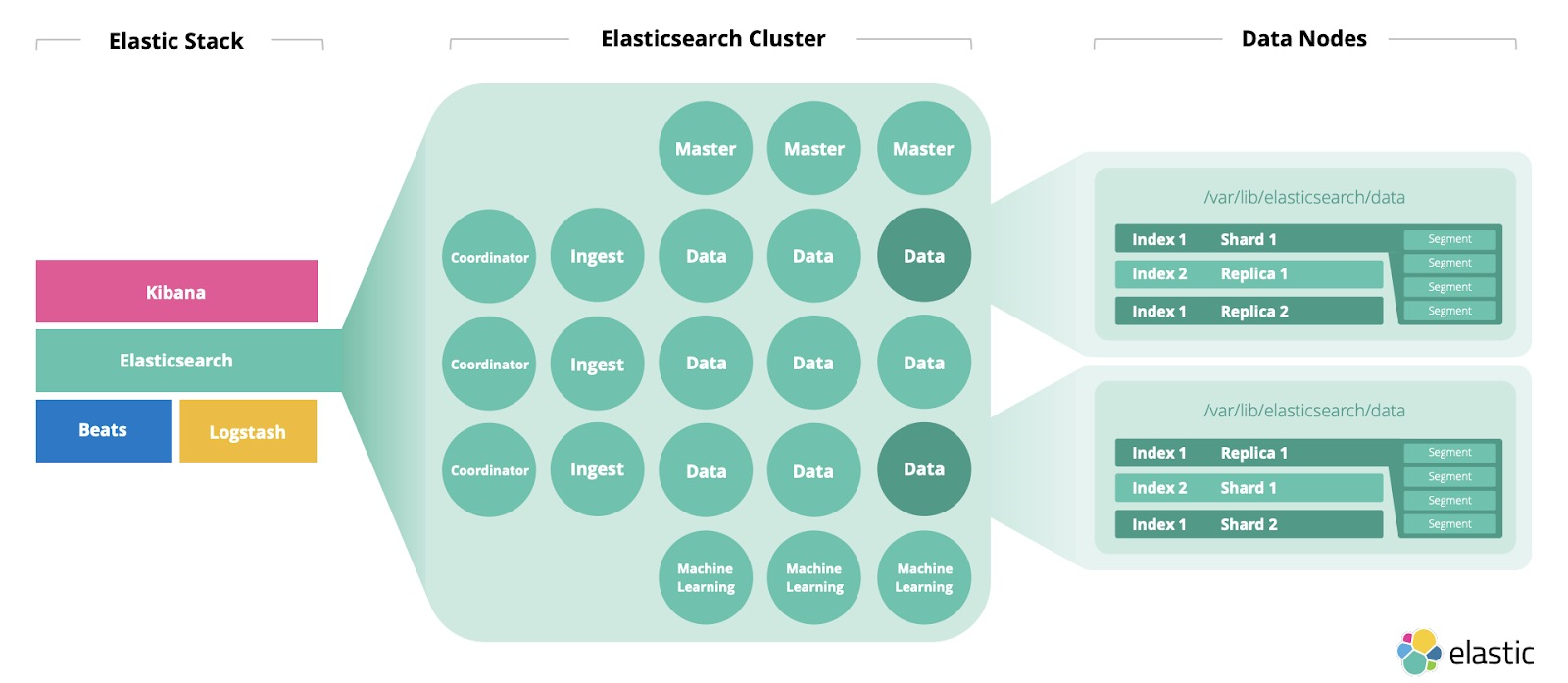
总体来讲,一个 Elasticsearch 集群(Cluster)由一个或多个节点(Node)组成,每个节点都是一个 Elasticsearch 实例。每个节点内部有任意多个分片(Primary Shard)和副本(Replica Shard),分片是把数据分布在多台机器上,用于突破单机限制,副本是冗余数据,用于高可用和提高吞吐量。
Elasticsearch 集群架构如下图所示(来自《Elasticsearch Sizing and Capacity Planning》):
集群(Cluster)
所有节点合在一起协同工作就是集群。(A collection of connected nodes is called a cluster.)
集群有三种健康状态:green、yellow、red:
- green:所有分片和副本都正常。
- yellow:主分片正常运行(集群可以正常服务所有请求),但是副本没有全部正常运行(不是高可用状态)。
- red:存在分片非正常运行(某些数据不可用),可能部分功能依然可用。
节点(Node)
每个节点都是一个 Elasticsearch 实例,由名称标识,启动时会生成唯一 UUID。
每个节点都知道集群内的其他节点,并可以把请求转发给合适的节点。
一台机器可以有多个节点,大多数情况下,每个节点运行在一个独立的容器或虚拟机里。
根据分工的不同,节点有不同的角色(node.roles),具体可以参考官方文档:《Node》。
分片(Primary Shard)
Elasticsearch 是一个分布式搜索引擎,会把索引(文档的集合)拆分到不同的节点上,也就是分片,相当于一桶水用 N 个杯子装。
每个节点内可以有零个、一个或多个分片,如下图所示(来自《Elasticsearch:权威指南 - 水平扩容》):
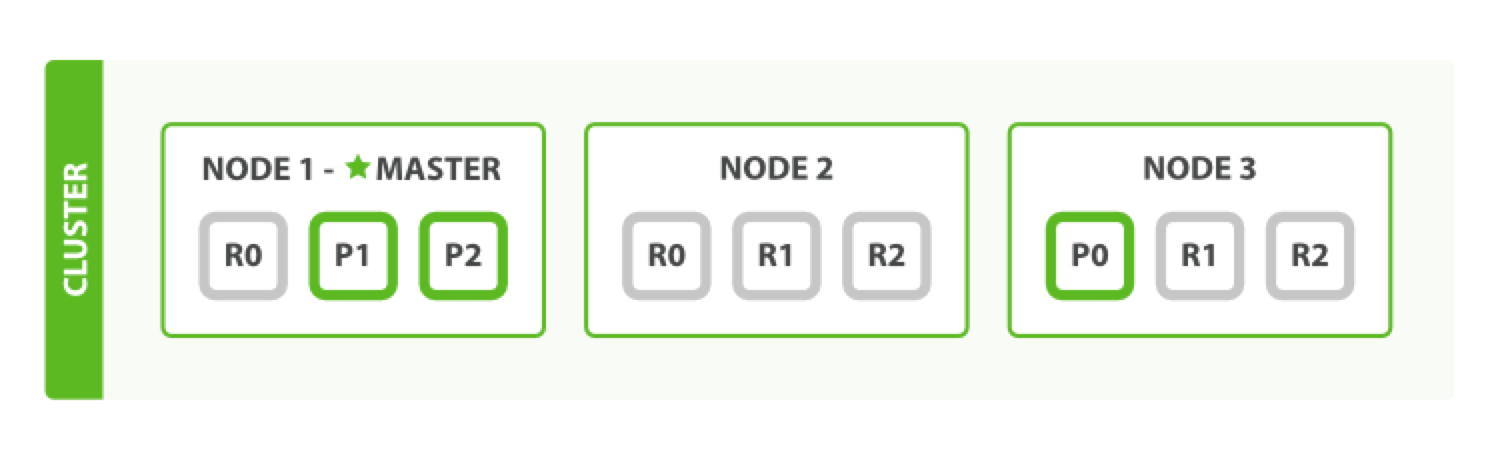
实际上每个分片都是一个 Lucene Index,受 Lucene 底层限制,每个分片只能存放
Integer.MAX_VALUE - 128个文档(21 亿多)。副本(Replica Shard)
副本是分片的拷贝(A replica shard is just a copy of a primary shard.),也就是备份,不接受索引请求,可以用于查询。
副本的作用一方面是容灾(高可用),另一方面副本可以用于查询,因此可以提高吞吐量(高性能)。
分片和副本不会出现在同一个节点上(防止单点故障)。默认情况下将为每个分片创建一个副本(但只有一个节点的话就不会)。
推荐阅读《在ElasticSearch中,集群(Cluster),节点(Node),分片(Shard),Indices(索引),replicas(备份)之间是什么关系?》
疑难名词解释
有两个名词:分片、索引,在不同的语境下语义也不同,很容易绕晕,下面特别提一下。
分片(Shard)
上面提到的分片和副本,准确翻译应该是主分片(Primary Shard)和副本分片(Replica Shard)(A shard can be either a primary shard or a replica shard.),也就是说它们俩都是分片。
在中文语境下,我们一般说到 Elasticsearch 分片时,实际上指的是主分片,而不同时指代两者,也就是分片用于分布式存储数据,而不是用于备份冗余。
索引(Index)
索引是一种预排序的数据结构,是数据库常见的概念。但是在不同的语境下,索引可能有特殊的含义。
MySQL 索引
我们通常想到索引时,想到的都是 MySQL 索引,代表着关系型数据库的存储数据结构,我们可以通过索引找到数据。
Elasticsearch 索引
在 Elasticsearch 的语境下,通常把索引理解成文档的集合(An Index is a group of documents.),而不光是一种数据结构。换句话说,Elasticsearch 认为索引 = 数据库,它代表着一个大容器。
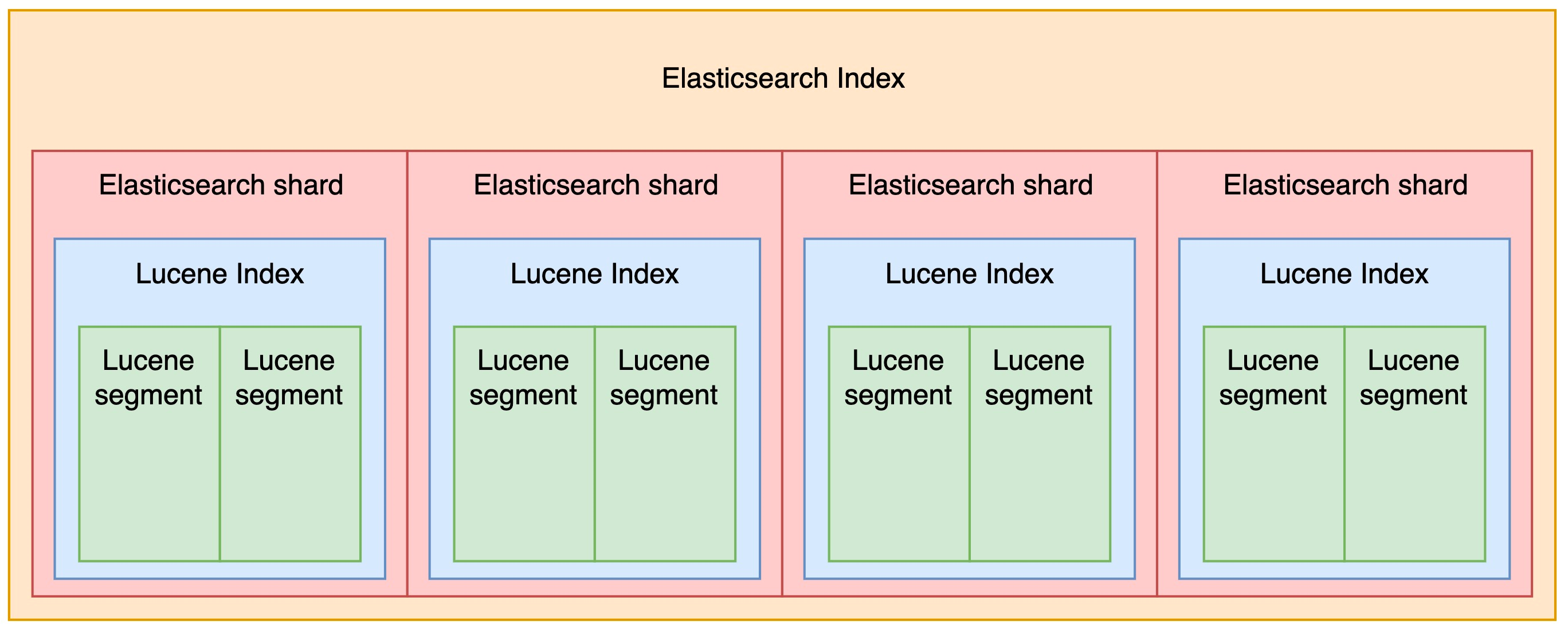
一个 Elasticsearch 索引分布在多个分片上,每个分片都是一个 Lucene 索引(这就是下面要提到的)。
Lucene 索引
在 Elasticsearch 语境下,分片 = Lucene 索引。
Lucene 索引内部由 Lucene 段(segment)和提交点(commit point)组成(the word index in Lucene means “a collection of segments plus a commit point”.)。当我们看到 segment 这个词时,可以简单理解为 Elasticsearch 底层的数据存储结构。
当学习 Elasticsearch 新增、查询数据时,会再次见到 Lucene 索引,到时具体分析 segment 的设计。
下图是 Elasticsearch 索引和 Lucene 索引的关系(来自《Getting Started with Elasticsearch》)。
全文搜索的底层:倒排索引
全文搜索是通过倒排索引实现的。
倒排索引对应于正排索引,下面举一个例子(这个例子来自于 ELasticsearch 官方文档《倒排索引》)。
假设有两个文档,每个文档的内容如下:
- The quick brown fox jumped over the lazy dog.
- Quick brown foxes leap over lazy dogs in summer.
通常用 MySQL 存储这两个文档,会这么存储(也就是正排索引):
| doc_id | content |
|---|---|
| 1 | The quick brown fox jumped over the lazy dog. |
| 2 | Quick brown foxes leap over lazy dogs in summer. |
倒排索引换了一个思路,把每个文档拆碎成一个个词,记录每个词在哪篇文档里出现过:
| term | doc_1 | doc_2 |
|---|---|---|
| Quick | ✅ | |
| The | ✅ | |
| brown | ✅ | ✅ |
| dog | ✅ | |
| dogs | ✅ | |
| fox | ✅ | |
| foxes | ✅ | |
| in | ✅ | |
| jumped | ✅ | |
| lazy | ✅ | ✅ |
| leap | ✅ | |
| over | ✅ | ✅ |
| quick | ✅ | |
| summer | ✅ | |
| the | ✅ |
使用倒排索引,我们能够根据词,找到哪些文档中包含这些词,从而实现全文搜索。试想一下,从 TB 量级的日志中,搜索包含某关键字的日志,使用倒排索引是不是很合适。
上面例子中的倒排索引,是一个最简单的倒排索引,实际上 Elasticsearch 还记录了词频(某个词在某文档中出现的次数,毕竟可能出现多次)、出现位置(是文档的第几个词)等信息。
Elasticsearch 有很多种数据类型(布尔、数字、地理位置等),其中使用倒排索引进行全文搜索的数据类型是 text(这应该是 Elasticsearch 最重要的数据结构了)。
Elasticsearch 把文本拆成词加入倒排索引的过程,叫做 Text analysis(文本分析),这部分组件叫做 analyzer。
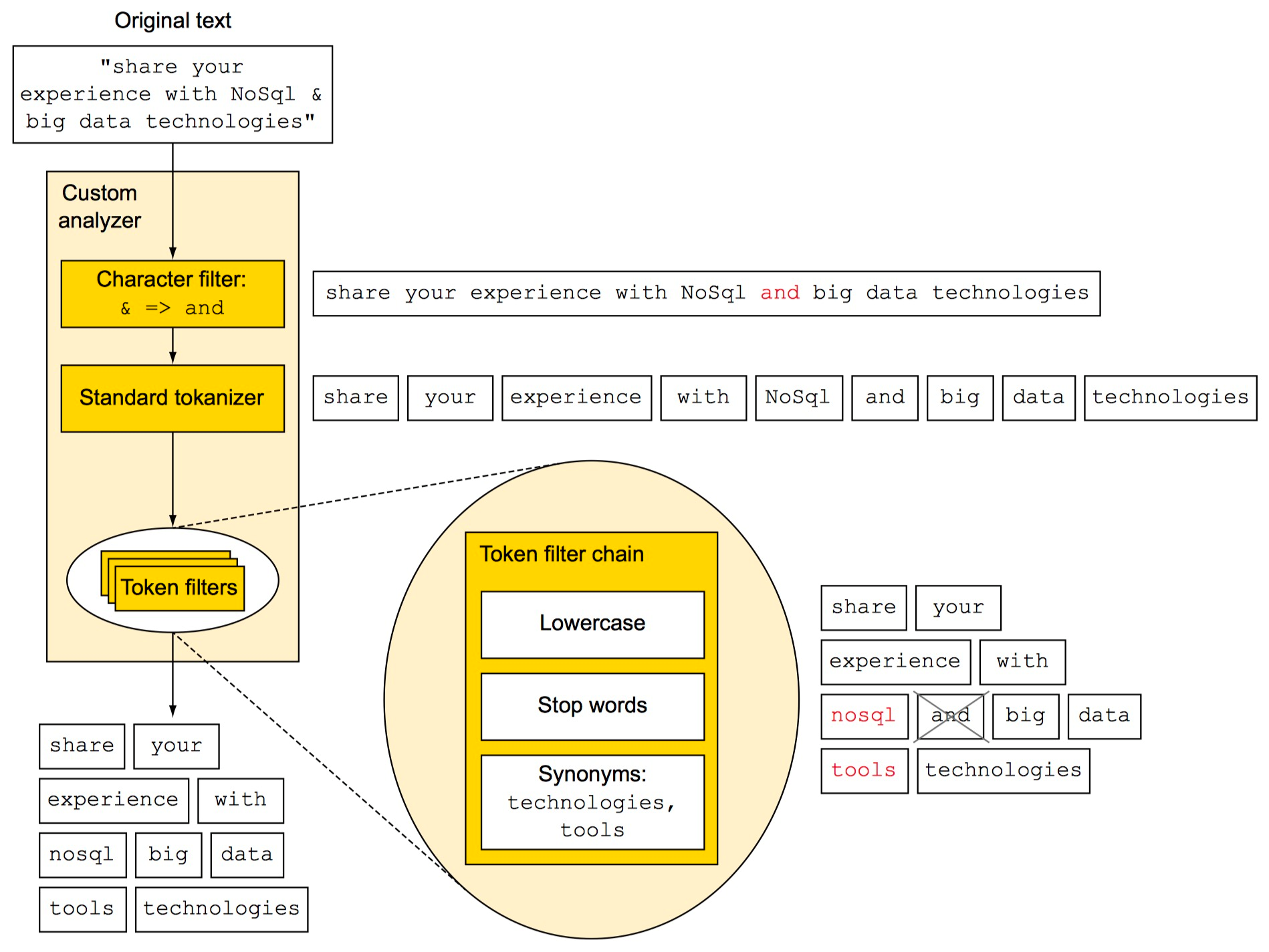
文本分析主要分为下面三步(官方文档《Anatomy of an analyzer》):
Character filters
特殊字符转换过滤。比如删除标点符号,又比如把
&替换成and。Tokenizer
分词。把文本拆成多个词或词组,不同的 analyzer 拆分逻辑不一样,取决于内部的分词器 tokenizer。
顺便一提,拆分出的词/词组,叫做 term 或 token。
Token fiters
分词结果转换过滤。比如把
Name替换成name,把无效词the删掉。
下图很好地概括了文本分析(来自《Elasticsearch in Action》):
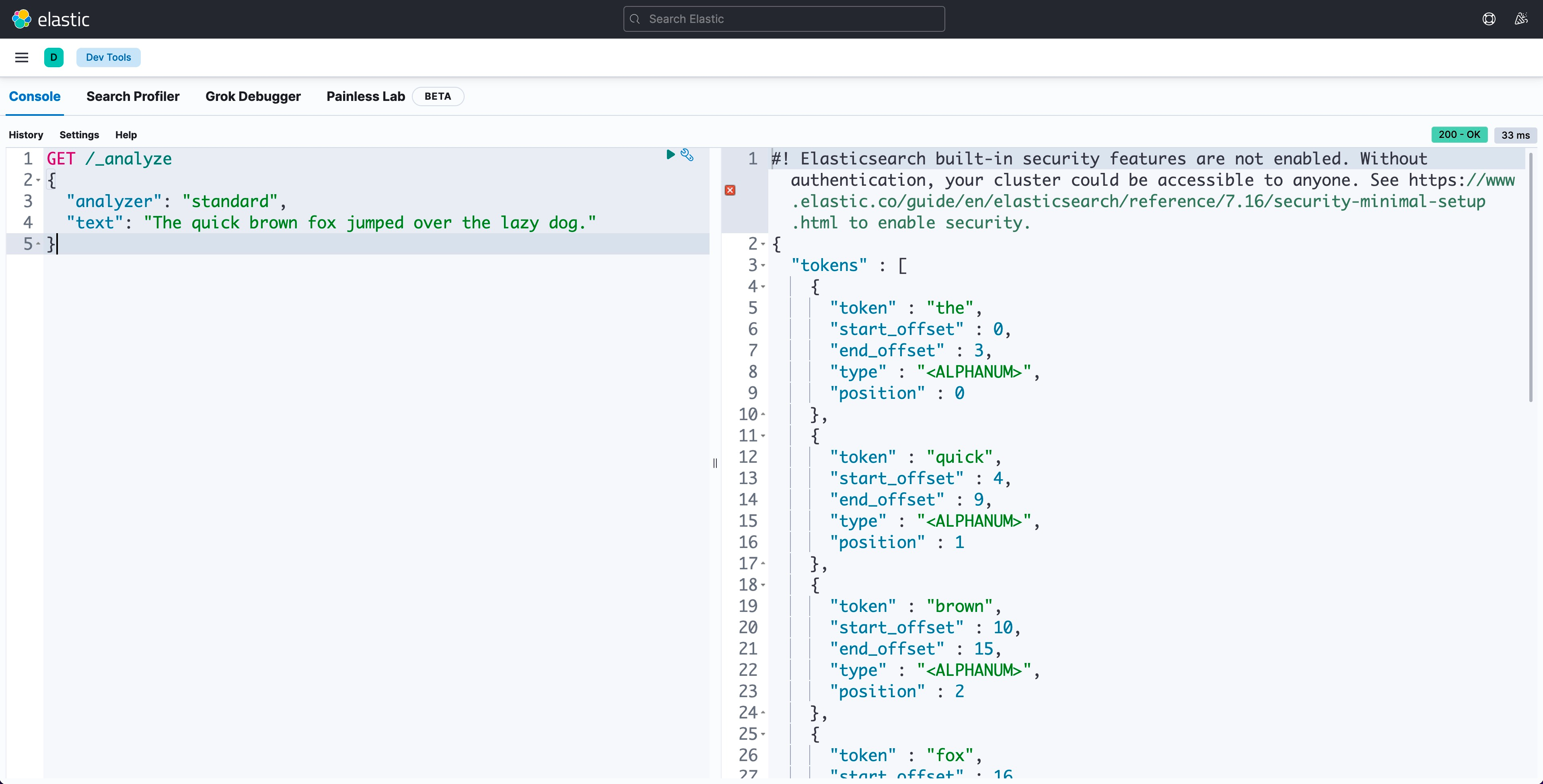
可以使用 Analyze API 测试 analyzer 是如何解析文本的,例如:
有关 Elasticsearch 文本分析,还可以参考社区文章《Elasticsearch: analyzer》。
Elasticsearch 实操
试着操作一下最简单的 CRUD:
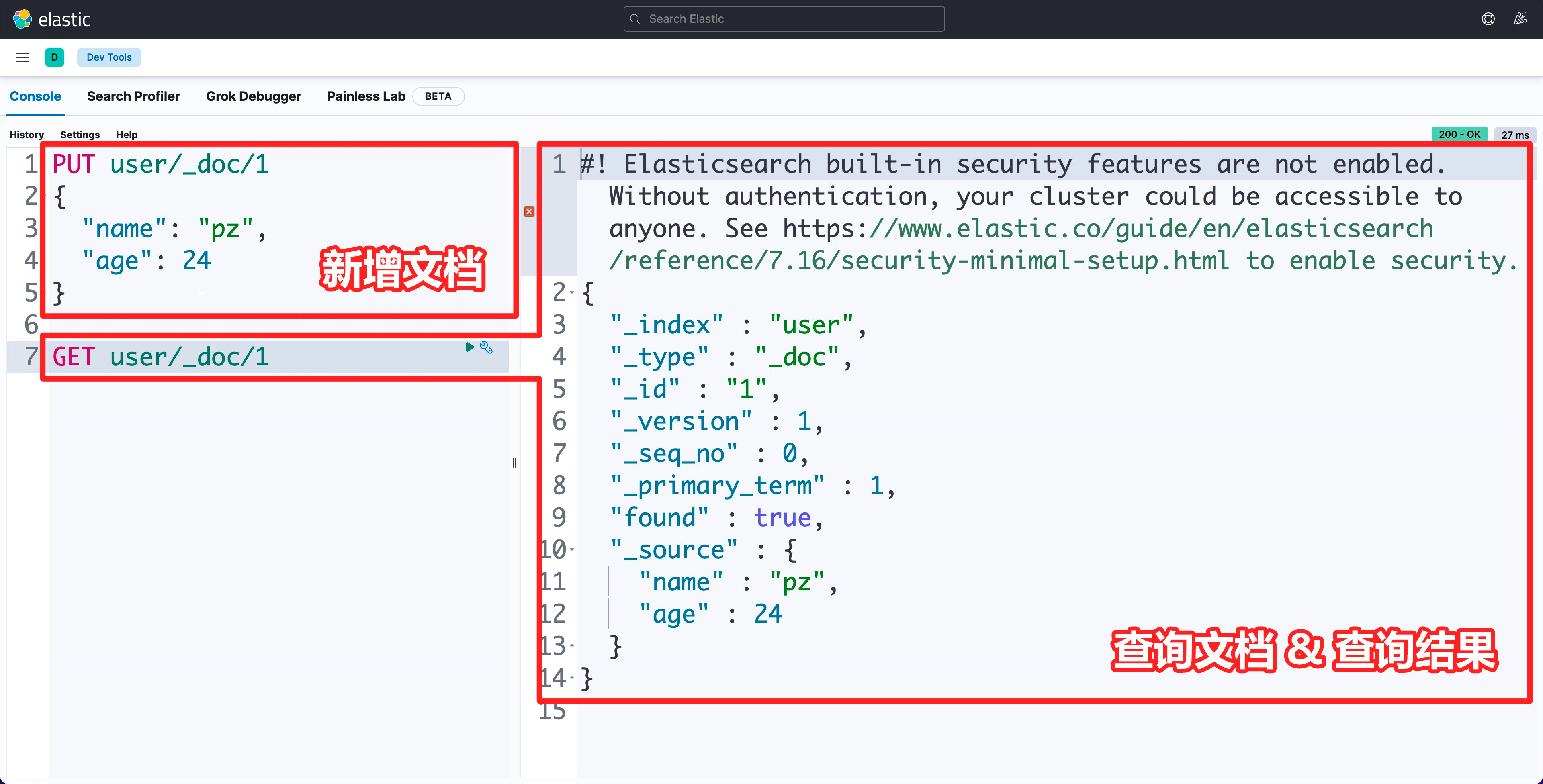
- 在 user 索引中增加一个文档:
name属性是pz,age属性是24。 - 查询这个文档
新增和查询命令的语法都很简单,看一下就能明白怎么回事,更复杂的 CRUD 之后再学习。
只提两个地方:
没有建表
Elasticsearch 是 scheme-less 的,不需要显式建表,如果 index 不存在,在创建第一条数据时,会自动创建 index、field 等内容,并自动关联上去。
当然也可以在写入第一条数据之前,先创建好 index 并规定好数据结构(生产环境肯定要这么做)。
如果纯靠 Elasticsearch 自动创建 index 和数据结构,会按照默认规则创建,可能会有差错(比如地理位置字段被识别成文本字段),而当文档已经存在之后,数据结构就不能再修改了。
Response body(返回体)包含元数据
Elasticsearch 的查询结果,除了文档本身,还有用于描述文档信息的元数据(meta-fields),它们以下划线开头(但是为什么有的字段没有下划线,我还没搞清楚)。
以查询文档的 GET 请求返回为例(可以参考官网文档《Get API - Response body》):
1
2
3
4
5
6
7
8
9
10
11
12
13{
"_index" : "user", // 文档(document)所在索引(index)的名称
"_type" : "_doc", // 文档类型,Elasticsearch 8.0 之后只能是 _doc,具体可见上文[基本概念-数据库相关]部分
"_id" : "1", // 文档 ID
"_version" : 1, // 文档版本号(document 的所有变动都会 +1)
"_seq_no" : 1, // 文档所在索引的版本号(index 的所有变动都会 +1)
"_primary_term" : 1, // 文档所在分片(shard)的编号
"found" : true, // 是否找到,只能是 true/false
"_source" : { // 文档内容
"name" : "pz",
"age" : 24
}
}
Elasticsearch 学习资料
整理一下学习资料。
官网文档
《Elasticsearch Guide》英文最新教学文档
《Elasticsearch: 权威指南》中文文档,版本 2.x
Elastic 中国社区官方博客
《Elastic:开发者上手指南》中文社区在 CSDN 上笔耕不辍,这篇是目录
第三方博客
《Elasticsearch 高手之路》xiaoxiami 的博客,内容不全面,选择性阅读