MySQL InnoDB 事务
三月的第一周,来学习 MySQL 的事务,包含事务、事务的隔离级别、redo 日志、undo 日志、MVCC 这些内容。
本周的学习来源还还还是《MySQL 是怎样运行的:从根儿上理解 MySQL》(写得太好了www)。
事务
事务(数据库事务的简称),是指一系列数据库操作组成的一个逻辑单元(也就是一个整体),这个逻辑单元符合四条特性:原子性(Atomicity)、隔离性(Isolation)、一致性(Consistency)和持久性(Durability)(英文首字母缩写为 ACID)。
下面四条 SQL 语句就属于一个事务:
1 | BEGIN; |
提交事务的方式
手动提交
通过
BEGIN手动开始一个事务,中间输入一些数据库操作,再通过COMMIT手动提交一个事务(就像上面那四条 SQL 一样),此外中途还可以通过ROLLBACK回滚事务(撤回事务里的全部操作)。还可以通过
START TRANSACTION开启一个事务,它跟BEGIN的作用是相同的,但是START TRANSACTION语句后边能跟随几个修饰符,相当于增强版的BEGIN。自动提交
默认情况下,MySQL 的每一条语句都是一个独立的事务,这是 MySQL 的系统变量
autocommit设置的(默认ON)。隐式提交
如果通过
BEGIN或START TRANSACTION开启一个事务,即使不输入COMMIT手动提交,在一些情况下也会隐式提交事务,例如ALTER USER、CREATE USER、SET PASSWORD、START SLAVE、FLUSH等等。
事务的隔离级别
两个事务有可能同时执行,比如事务 A 执行到一半,事务 B 开始执行,如果它们操作了同一条数据,就会造成一些意想不到的情况。
有四种因为事务并发执行带来的意想不到的情况(以下将事务 A 简写成 A,事务 B 简写成 B):
- 脏写:A 修改了 B 修改过(未提交)的数据(这是非常严重的行为,在所有情况下都应该避免)
- 脏读:A 读到了 B 修改过(未提交)的数据
- 不可重复读:A 读到了 B 修改过(已提交)的数据,即每次都能读到已提交事务的最新值
- 幻读:A 读到了 B 修改过(已提交)的数据,且这些数据原来不存在,是新查出来的
为了避免这些情况,事务有四种隔离级别,详见下表:
| 未提交读 (READ UNCOMMITTED) |
已提交读 (READ COMMITTED) |
可重复读 (REPEATABLE READ) |
可串行化 (SERIALIZABLE) |
|
|---|---|---|---|---|
| 脏写 | 不可能发生 | 不可能发生 | 不可能发生 | 不可能发生 |
| 脏读 | 不可能发生 | 不可能发生 | 不可能发生 | |
| 不可重复读 | 不可能发生 | 不可能发生 | ||
| 幻读 | 不可能发生 |
InnoDB 是怎么实现这四种隔离级别的,要等到最后才能讲到。
顺便一提,不是所有 MySQL 存储引擎都支持事务,InnoDB 支持事务,而 MyISAM 就不支持。不支持的存储引擎也不会报错,BEGIN、ROLLBACK 之类的操作也都是可以执行的,只不过没有效果。
有关事务的概念,可以参考《廖雪峰博客 - 事务》,整理得很干练。
事务持久化:redo 日志
补知识
数据库最终存储在磁盘当中,但 InnoDB 使用 Buffer Pool(缓存池)暂存磁盘中的数据。Buffer Pool 实际上就是一块内存空间,默认 128MB。
InnoDB 读取数据,从磁盘中拷贝到 Buffer Pool 里,以后就可以直接从 Buffer Pool 中查询这些数据。
InnoDB 修改数据,先在 Buffer Pool 中修改(修改完的部分被叫做“脏页”),后台线程不断地把脏页写回磁盘,这个过程是异步的。
使用 Buffer Pool 的原因是磁盘太慢了,尤其是随机读写更是慢,如果查询一条数据就去磁盘搜索,或者更新一条数据就去磁盘保存,阻塞的时间太长了。为了避免这种情况,InnoDB 根据局部性原理引入缓存的概念,把用过的数据缓存在 Buffer Pool 中。
Buffer Pool 的数据结构类似于 LinkedHashMap,由多个 LRU 双向链表构成,并通过哈希查找缓存页。
redo 日志的作用
InnoDB 的增删查改操作都是先操作 Buffer Pool,再由后台线程异步保存进磁盘,这是为了避免磁盘 IO 带来的龟速。但是数据不保存到磁盘里,如果服务器突然宕机,那么还没保存的 Buffer Pool 脏页数据就会丢失,事务的持久性就无法实现。
数据一定要保存进磁盘里,才能保证事务的持久性,那就想个办法,让磁盘保存得快一点。
redo 日志(redo log)记录了数据库做了哪些操作,比如记录了将第 0 号表空间的 100 号页面的偏移量为 1000 处的值更新为 2 这个行为。数据库执行一条操作,redo 日志就记录一条操作,如果宕机了,根据 redo 日志把之前的操作重做一遍就可以了。
【保存 redo 日志进数据库】比【保存数据进数据库】快很多,有两方面的原因:
- InnoDB 以页为单位保存进磁盘,如果直接保存数据,即使改一个字节也要保存一页 16 KB 的数据,但是保存 redo 日志可以少很多(后面提)。
- redo 日志是顺序写入磁盘的,磁盘的顺序读写比随机读写快多了。
redo 日志的保存过程
为了避免数据写入磁盘太慢,InnoDB 引入了 Buffer Pool 的概念,将修改的页先缓存下来。
同理,为了避免 redo 日志写入磁盘太慢,InnoDB 引入了 redo log buffer 的概念(简称 log buffer),将 redo 日志先缓存下来(不用担心,事务提交时会确保写入磁盘的)。
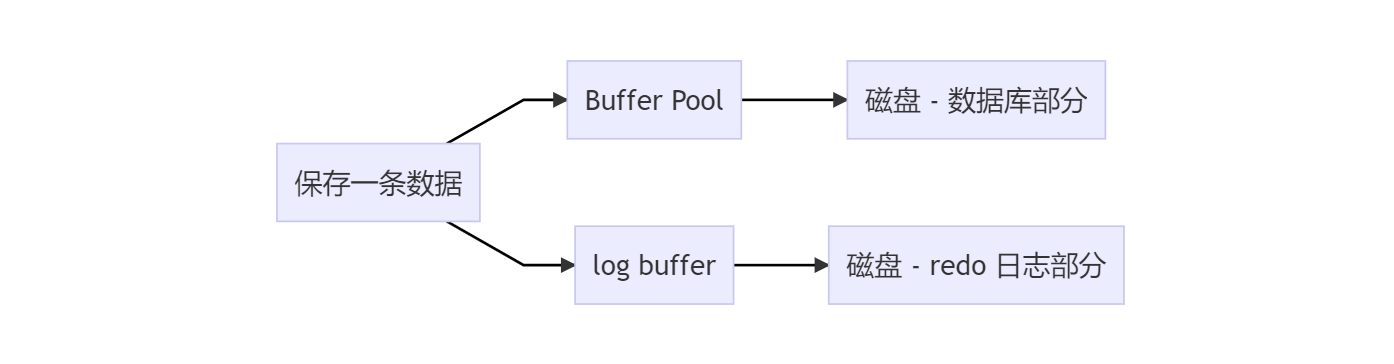
InnoDB 修改的数据,可能会出现在上图的 Buffer Pool、log buffer、磁盘 - 数据库部分、磁盘 - redo 日志部分里。
简单想通两个逻辑:
- 如果 redo 日志已经保存进磁盘了,那么缓存就可以删除了(在
log buffer中删除)。 - 如果真正的数据已经保存进磁盘了,那么 redo 日志就可以删除了(缓存和磁盘里都可以删除)。
对应这两种情况,InnoDB 提出两个 LSN(log sequence number),方便清理存储空间:
- flushed_to_disk_lsn:redo 日志已经刷入到磁盘的字节数
- checkpoint_lsn:真正的数据已经写入磁盘,对应的 redo 日志的字节数
redo 日志从 log buffer 刷入到磁盘的时机如下:
log buffer内存不足(启动参数默认 16KB)- 事务提交
- 后台线程一直刷入磁盘
- 正常关闭服务器
- 磁盘空间不够用,做 checkpoint
- ……
为了保证事务的持久性,每次提交事务都要将 redo 日志保存到磁盘里,实际上磁盘 IO 还是很慢的。如果对持久性需求不强烈,可以修改系统变量 innodb_flush_log_at_trx_commit,事务提交时不刷入磁盘(数据库挂了,操作系统没挂,还是可以恢复的)。
(本来我是想画一下 redo 日志的数据结构,以及数据是怎么保存进 buffer 又保存进磁盘的,但是我太懒了hhh,就抛一个链接吧《MySQL 是怎样运行的:从根儿上理解 MySQL - redo日志》)
事务回滚:undo 日志
undo 日志的作用
事务回滚指的是,放弃所有修改,使数据库状态恢复到事务开启之前的时刻,就好像事务从来没发生过一样。
InnoDB 实现事务回滚的方式是,把操作反过来执行一遍:事务执行插入操作,回滚时就执行删除操作,事务执行修改操作,回滚时就把数据修改回来。也就是说,实际上 InnoDB 执行的不是撤销操作,而是反向操作,最终效果等同于撤销,好像什么都没执行过一样。
这些反向操作,InnoDB 记录下来,称作 undo 日志(undo log),在事务回滚的时候,就执行 undo 日志的内容。
undo 日志的类型
总体有三类 undo 日志,分别对应着 INSERT 操作、UPDATE 操作、DELETE 操作(查询没有 undo 日志,因为查询不用回滚):
INSERT 操作
数据库插入数据,undo 日志就记录一条删除操作,类型为
TRX_UNDO_INSERT_REC,这条日志记录了插入数据的主键。DELETE 操作
数据库删除数据,undo 日志就记录一条插入操作,类型为
TRX_UNDO_DEL_MARK_REC,这条日志记录了删除数据的所有信息。UPDATE 操作
UPDATE 分为两种,分别是更新主键和不更新主键:
- 更新主键的话,由于聚簇索引的调整比较复杂,因此实际的操作是先删除再插入,最终达到更新的效果。这样会生成两条 undo 日志,先生成 DELETE 操作对应的日志,再生成 INSERT 操作对应的日志。
- 不更新主键,原地更新就可以了,undo 日志记录一条更新回去的操作,类型为
TRX_UNDO_UPD_EXIST_REC,这条日志记录了更新数据的主键信息,和需要更新的字段原来的信息。
注意一下,undo 日志实际上记录了很多信息,不仅仅包含反向修改数据的信息,还包含比如地址、日志类型、undo 编号等等信息。
undo 日志的工作逻辑
要回忆一条很久远的知识,最初学习 InnoDB 数据结构时,我画了一张 Compact 行格式的图,这是聚簇索引的叶子节点:
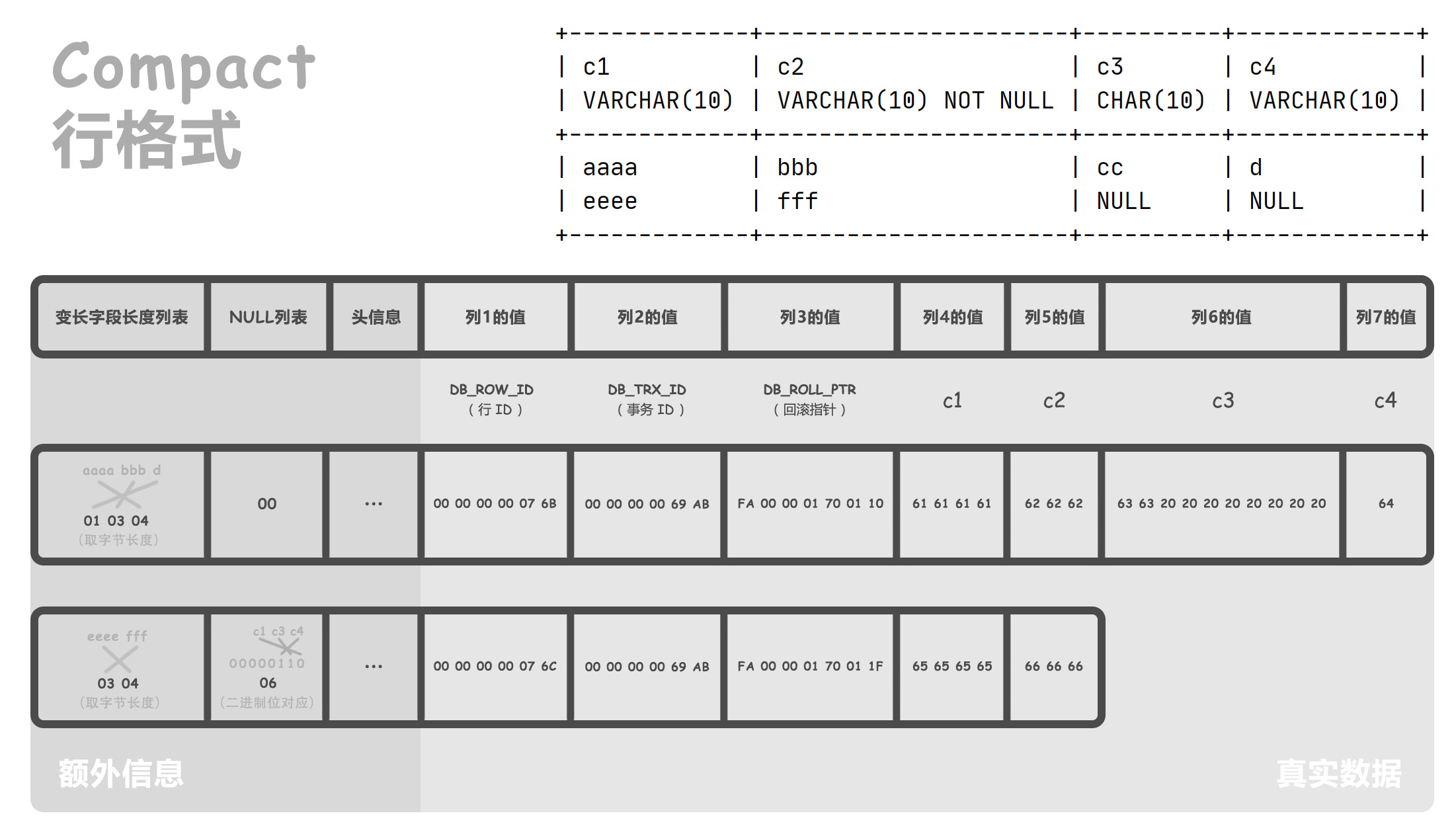
数据库中的每一条数据,最终在磁盘中会被存储成这个样子。
当时我们忽略了事务 ID 和回滚指针这两个字段,现在就能用得上了。
事务 ID(DB_TRX_ID)
事务 ID 是一个全局字段,数据库在内存中维护一个全局变量,每次需要为某个事务分配一个事务 ID 时,就会把该变量当做事务 ID 分配给该事务,并把该变量自增 1。
回滚指针(DB_ROLL_PTR)
这个字段是一个指针,指向它对应的 undo 日志的地址。
也就是说,如果要回滚这条数据,可以通过这个字段找到 undo 日志,从而实现回滚(实际上设计得更精妙)。
下图是《MySQL 是怎样运行的:从根儿上理解 MySQL》画的示意图:
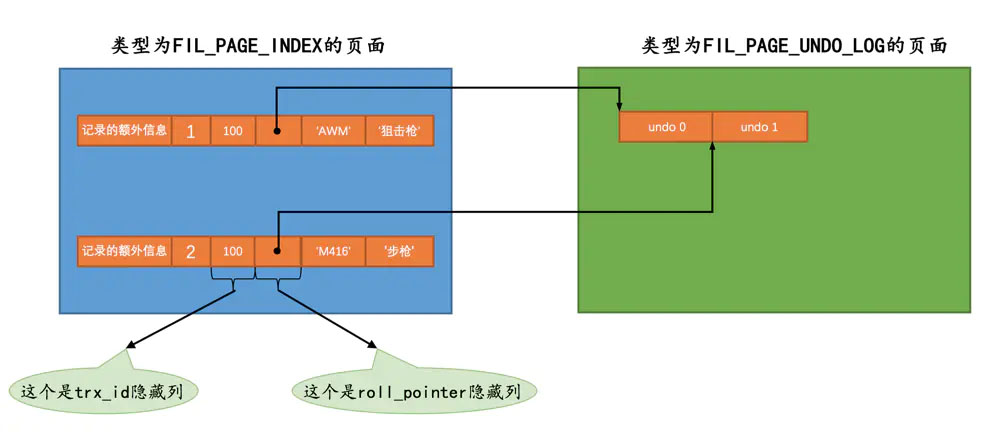
实际上,undo 日志内部还有一个
roll_pointer属性,它指向更早的 undo 日志。比如这两句 SQL:
1
2INSERT INTO t_user(user_id, name, age) VALUES (1, "张三", 18);
UPDATE t_user SET name = "李四" WHERE user_id = 1;首先插入一条数据(生成一条 INSERT 操作的 undo 日志),然后更改这条数据(生成一条 UPDATE 操作的 undo 日志)。
第二条语句生成的 undo 日志,内部有一个
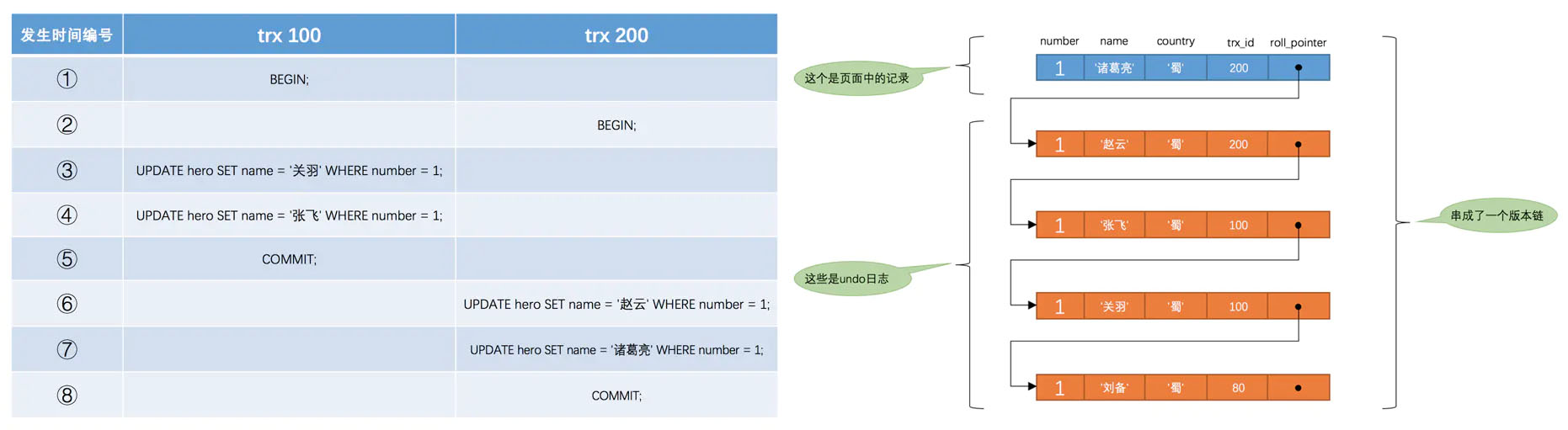
roll_pointer属性,它指向第一条语句生成的 undo 日志。再举一个例子,下图是《MySQL 是怎样运行的:从根儿上理解 MySQL》画的示意图:
InnoDB 实现事务的隔离级别
MySQL 有 4 种事务的隔离级别,分别拦住了四种由于事务并发造成的异常情况,详见下表:
| 未提交读 (READ UNCOMMITTED) |
已提交读 (READ COMMITTED) |
可重复读 (REPEATABLE READ) |
可串行化 (SERIALIZABLE) |
|
|---|---|---|---|---|
| 脏写 | 不可能发生 | 不可能发生 | 不可能发生 | 不可能发生 |
| 脏读 | 不可能发生 | 不可能发生 | 不可能发生 | |
| 不可重复读 | 不可能发生 | 不可能发生 | ||
| 幻读 | 不可能发生 |
这四种隔离级别,InnoDB 基本是通过 undo 日志的版本链实现的,具体实现如下:
未提交读(READ UNCOMMITTED)
允许读到其他事务未提交的数据,因此随便读,不用管事务。
已提交读(READ COMMITTED)
允许读到已提交事务的数据,因此读数据之前要判断一下事务 ID,如果是已提交的事务就可以读,如果是未提交的事务,就要根据 undo 版本链一路往前找,直到找到提交的事务。
实际上,这部分的实现更复杂一些,需要引入 ReadView 的概念(有点像快照),具体移步《MySQL 是怎样运行的:从根儿上理解 MySQL - 事务隔离级别和MVCC》。
可重复读(REPEATABLE READ)
可重复读和已提交读,基本是相同的,只不过生成 ReadView 的时机不一样。
- 已提交读:每次读取数据之前,都生成一个 ReadView
- 可重复读:第一次读取数据之前,生成一个 ReadView
可串行化
这种隔离级别最为严苛,直接上锁。
MySQL 默认的事务隔离级别是可重复读(REPEATABLE READ)。
这周就写到这里。
InnoDB 系列暂时就到这里了,如果以后要学习 MySQL 集群和分片相关的知识,再写新的内容。