MySQL InnoDB 索引
二月的第一周,来学习 InnoDB 的索引设计。
本周的学习来源还是《MySQL 是怎样运行的:从根儿上理解 MySQL》,瑞思拜。
InnoDB 为每个索引创建一个 B+ 树,每个节点都是一个索引页,其中包含若干 Compact 数据行。
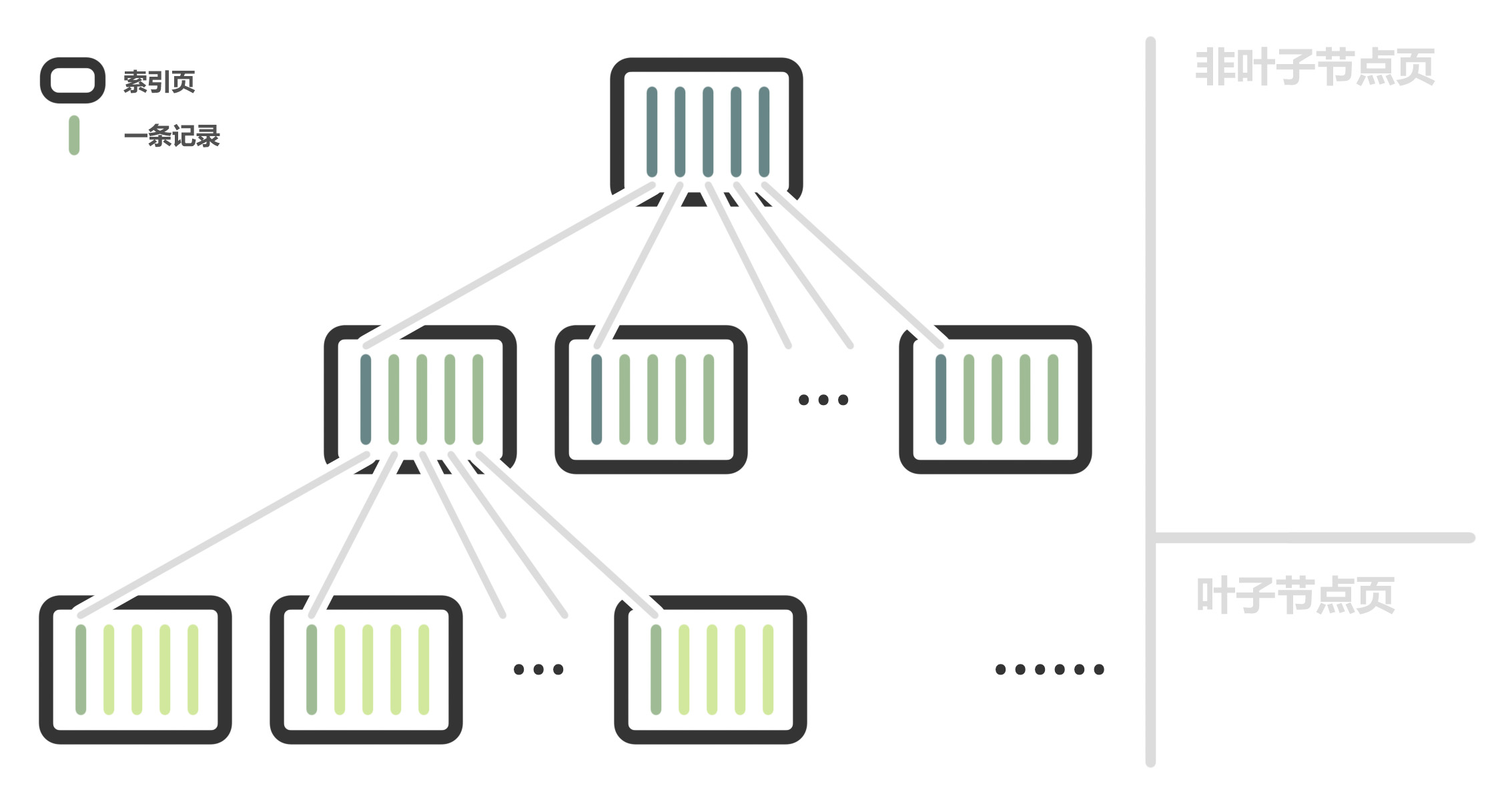
有两种索引,一种是主键(聚簇索引),一种是其他索引(二级索引)。
聚簇索引
比如一张表有 10000 行记录,用于区分每一行记录的唯一标记,就被叫做聚簇索引。
- 如果这张表有主键,就用主键做聚簇索引
- 如果这张表没有主键,选一个 Unique 键做聚簇索引
- 如果连 Unique 键都没有,InnoDB 生成一个隐藏键,做聚簇索引
每张表都必有聚簇索引,而且只有一份,通过它可以找到这张表的任意一条记录。
二级索引
除了聚簇索引之外,其他索引都是二级索引。
每个二级索引,可以包含一个或多个键(多个键也就是联合索引)。
索引数据结构
索引的作用是快速查找数据,如果没有索引,在数据库中查询一条记录,只能遍历全表(时间复杂度 O(N)),有了索引之后,数据库的存储结构变成一个 B+ 树,查询时类似于二分查找(时间复杂度 O(lgN)),查询速度大大提高。
InnoDB 使用 B+ 树作为索引的数据结构,这棵 B+ 树的作用就是快速查询,因此为了不浪费多余的空间,B+ 树除了叶子节点之外的节点,都不需要存储具体的数据信息,只需要存储“如何找到子节点”的信息(也就是页号)。换句话说,一个数据库可能有多个索引,有多少索引就有多少棵 B+ 树,但是所有的 B+ 树都不需要存储具体数据信息,即使需要,存一份也就够了,不要浪费空间。
具体存储信息如下:
| 非叶子节点 | 叶子节点 | |
|---|---|---|
| 聚簇索引 | 主键 + 子节点指针 | 全部信息 |
| 二级索引(单字段) | 索引字段 + 子节点指针 | 索引字段 + 主键 + 子节点指针 |
| 二级索引(联合索引) | 索引字段1 + 索引字段2 + … + 子节点指针 | 索引字段1 + 索引字段2 + … + 主键 + 子节点指针 |
索引查询逻辑
聚簇索引和二级索引,查询的主逻辑都是相同的,都是从 B+ 树的根节点,一层层查下去,一直查到叶子节点,整体查询效率是 O(lgN)。
以掘金小册中的配图为例(这只是示意图),查询索引值为 6 的记录,从第一层的页 44,查到第二层的页 42,再查到第三层的页 36,发现该记录在页 36 的第二条。
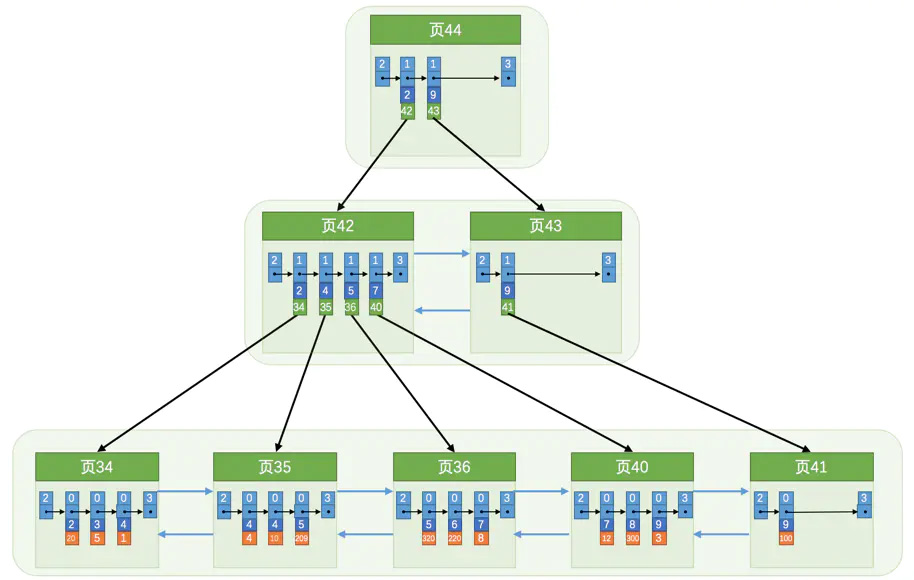
聚簇索引和二级索引的查询稍有不同,体现在最终如何找到完整的数据。
聚簇索引
下图是聚簇索引的查询过程,每一个方框都是一页,里面存放多个索引行。查询主键为某值的记录时,从根节点开始查找,最终找到叶子节点中的记录(这里一共三层)。
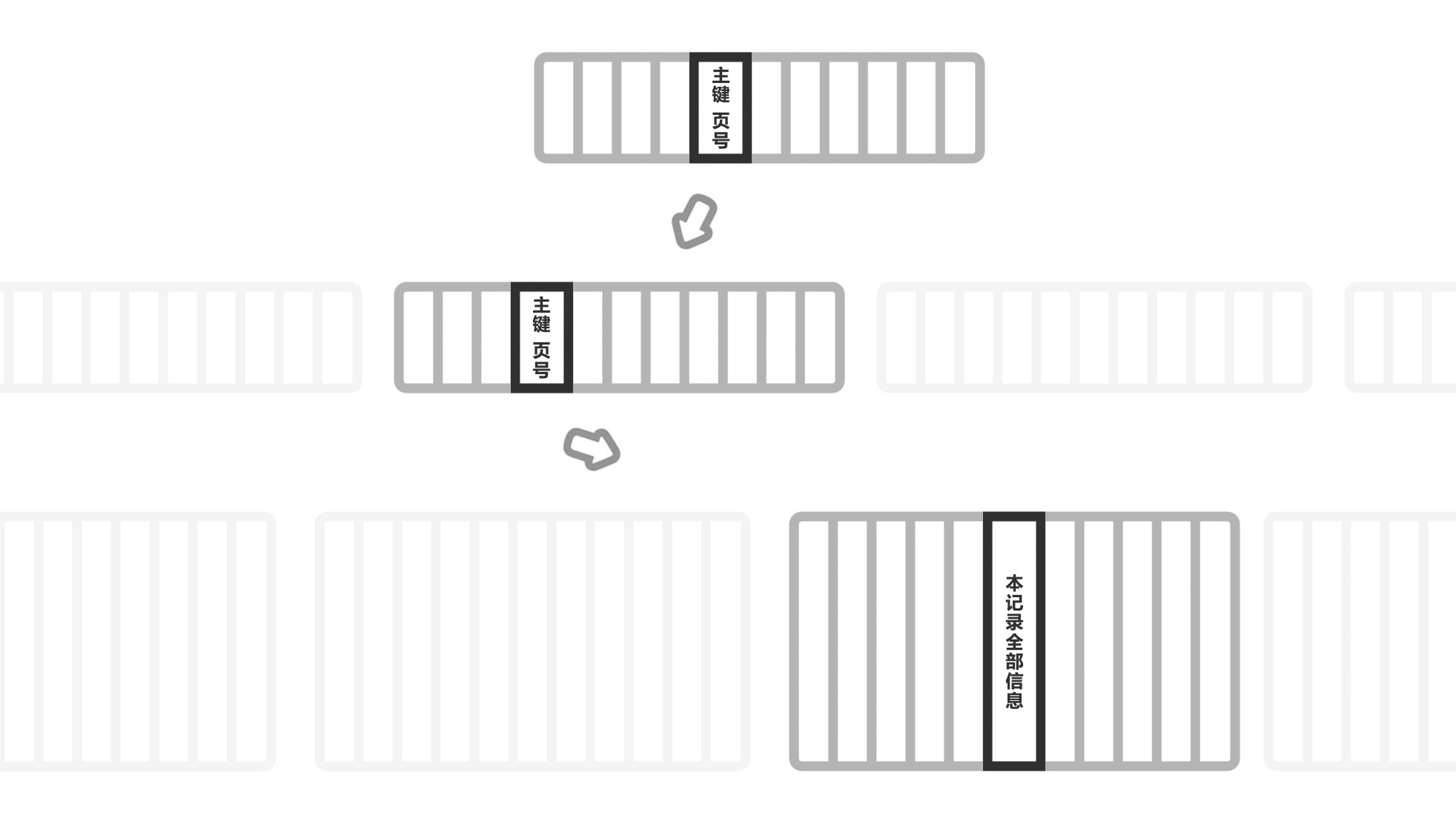
要注意的是,除了最下面一层的叶子节点,包含记录的全部信息之外,其他层的非叶子节点,都是不包含全部信息的,只包含了主键和页号信息(当然还有一些头信息,但这里略过),这样做是既是为了节省查询空间,也是为了节省查询次数。
在 InnoDB 的聚簇索引实现中,叶子节点包含了记录的全部信息,也就是说顺着聚簇索引一直查下去,就直接能查到这条记录的全部信息。还有一些存储引擎不是这么做的,比如 MyISAM 就把记录的全部信息单独存放在另外一片区域,通过聚簇索引查询到最后,还需要通过指针,到另一片存储区域找到记录的全部信息。
二级索引
二级索引的查询逻辑,比聚簇索引复杂一点点。
下图是二级索引的查询过程,整体跟聚簇索引基本一样,但查到叶子节点时,只有这条记录的主键值,而没有这条记录的全部信息。还需要再通过主键的值,去聚簇索引那里查到记录的全部信息,这一步被称为 回表。
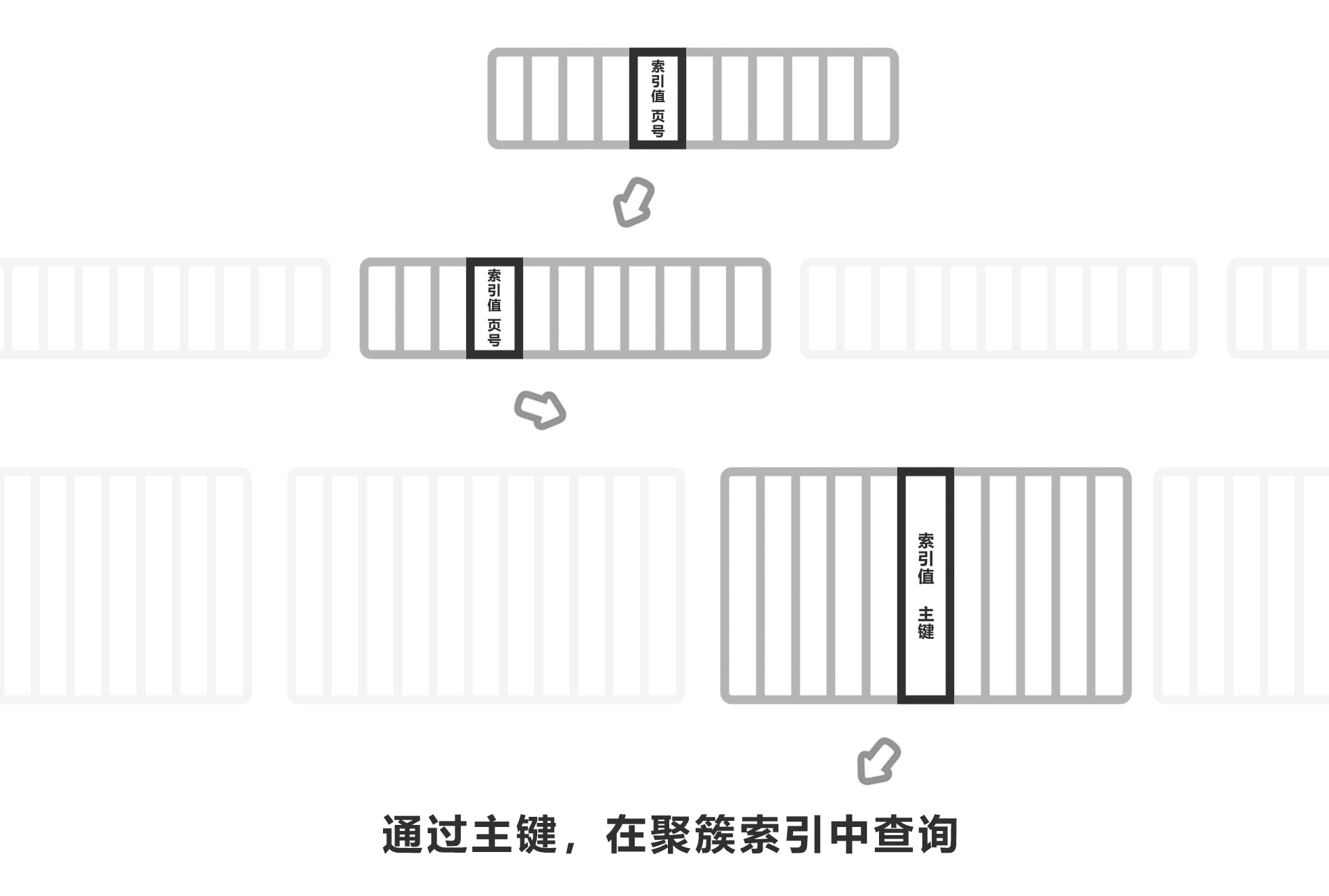
回表是为了省空间,如果一张表有 10 个索引,为每个索引都单独存储一份完整的记录信息,实在是太浪费空间了。聚簇索引通常只有几层而已,查询速度很快,回表并不会增加多少查询时间。
但是当查询数据的数量变多时,例如查询年龄在 18-60 岁之间的人群,可能会查到数万条记录,每条记录都要回表查询,这样查询的代价就大多了。因此查询时不要写 select * from ...,而是写到确切的字段 select age from ...,这样不需要查到全部信息,也就不需要回表,省下了大量的查询时间。
记录一些常见的问题。
为什么 InnoDB 使用 B+ 树
通常回答的原因是,因为 B+ 树比 B 树层数少了很多,能够减少查询次数,减少 I/O 操作,此外还支持范围查询。
我自己的看法是,这个问题要放在整个 InnoDB 的设计中来看,InnoDB 的最小单位是页,一页 16 KB,按照页这一存储单位来设计数据结构,好像也只能设计出 B+ 树了,这是很顺理应当的事情。
使用索引有什么规范
以下内容都来源自《MySQL 是怎样运行的:从根儿上理解 MySQL》
- B+ 树索引在空间和时间上都有代价,所以没事儿别瞎建索引。
- B+ 树索引适用于下边这些情况:
- 全值匹配
- 匹配左边的列
- 匹配范围值
- 精确匹配某一列并范围匹配另外一列
- 用于排序
- 用于分组
- 在使用索引时需要注意下边这些事项:
- 只为用于搜索、排序或分组的列创建索引
- 为列的基数大的列创建索引
- 索引列的类型尽量小
- 可以只对字符串值的前缀建立索引
- 只有索引列在比较表达式中单独出现才可以适用索引
- 为了尽可能少的让
聚簇索引发生页面分裂和记录移位的情况,建议让主键拥有AUTO_INCREMENT属性。 - 定位并删除表中的重复和冗余索引
- 尽量使用
覆盖索引进行查询,避免回表带来的性能损耗。
(2021.04.11 补)
B+ 树和 B 树有什么区别,为什么使用 B+ 树?
首先,B 树也可以叫做 B- 树,因为 B 树的英文名是 B-tree。
B+ 树是 B 树的一种变种,它们都是多路平衡查找树,但是 B 树的每个节点都有 key 和 value,而 B+ 数只有最深层的节点有 key 和 value,其他层都只有 key。
下图是《Difference between B tree and B+ tree》中的配图:
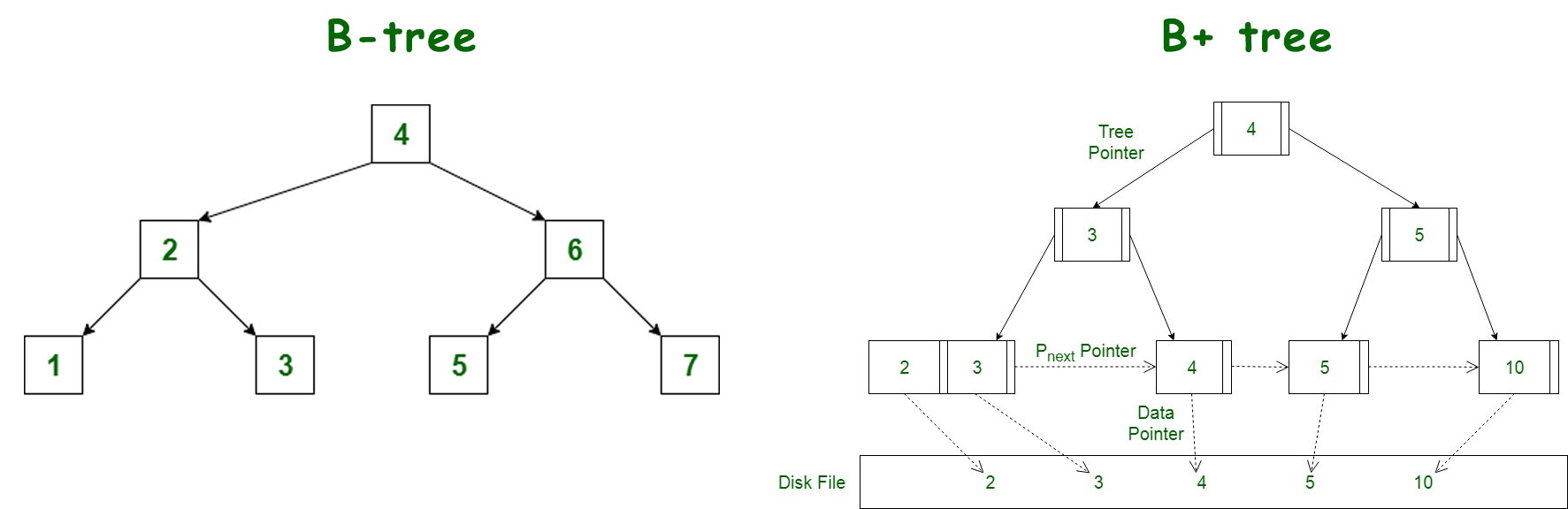
下图是《What are the differences between B trees and B+ trees?》中的配图:
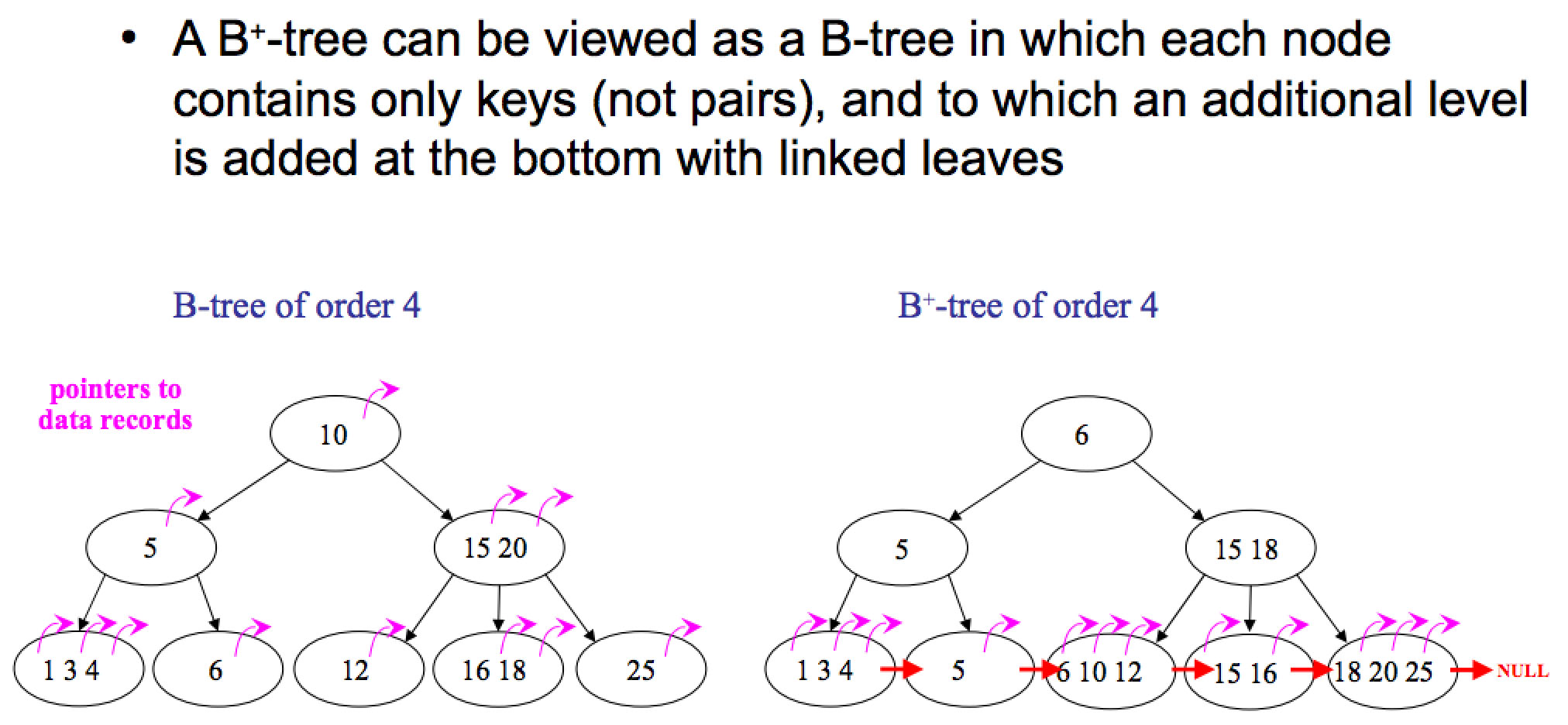
B+ 树相比 B 树的优势在于:
- B+ 树由于非叶子节点只存 key,因此每一层可以存更多组,树的深度变少了
- B+ 树的叶子节点是链表,可以方便地实现范围查找,而 B 树范围查找需要 DFS。