MySQL InnoDB 数据存储结构
新年的第四周,来学习 MySQL 默认存储引擎 InnoDB。
这一周从数据存储结构入门,学习 MySQL 是怎么存储数据的。
我学习 MySQL 基本全部来源自《MySQL 是怎样运行的:从根儿上理解 MySQL》,这是本电子书,下面的绝大多数图片、表格、内容都来源自本书,这本书写得非常详尽,是我最近一年读过最好的书。
MySQL 数据库,从宏观看到微观,最大的是表空间(最大 64TB),表空间中有若干个组(256MB),一个组中有 256 个区(1MB),一个区中有 64 个页(16KB),一个页中有若干行,每一行都是一条数据。
行是 MySQL 中最小的单位,代表一条数据,比如下面这个数据库,体现在存储上就是两行数据。
1 | +----+-----+------+------+ |
我们从 MySQL 最小的单位行,一直往大学习,最后学习到表空间。
行
MySQL 表中的一条数据,存储方式被称为行格式,MySQL 5.0 之后默认的行格式是 Compact。除了 Compact 行格式外,还有三种,原理大致相同,下面只学习 Compact 行格式。
以两条数据为例,做了一张示意图:
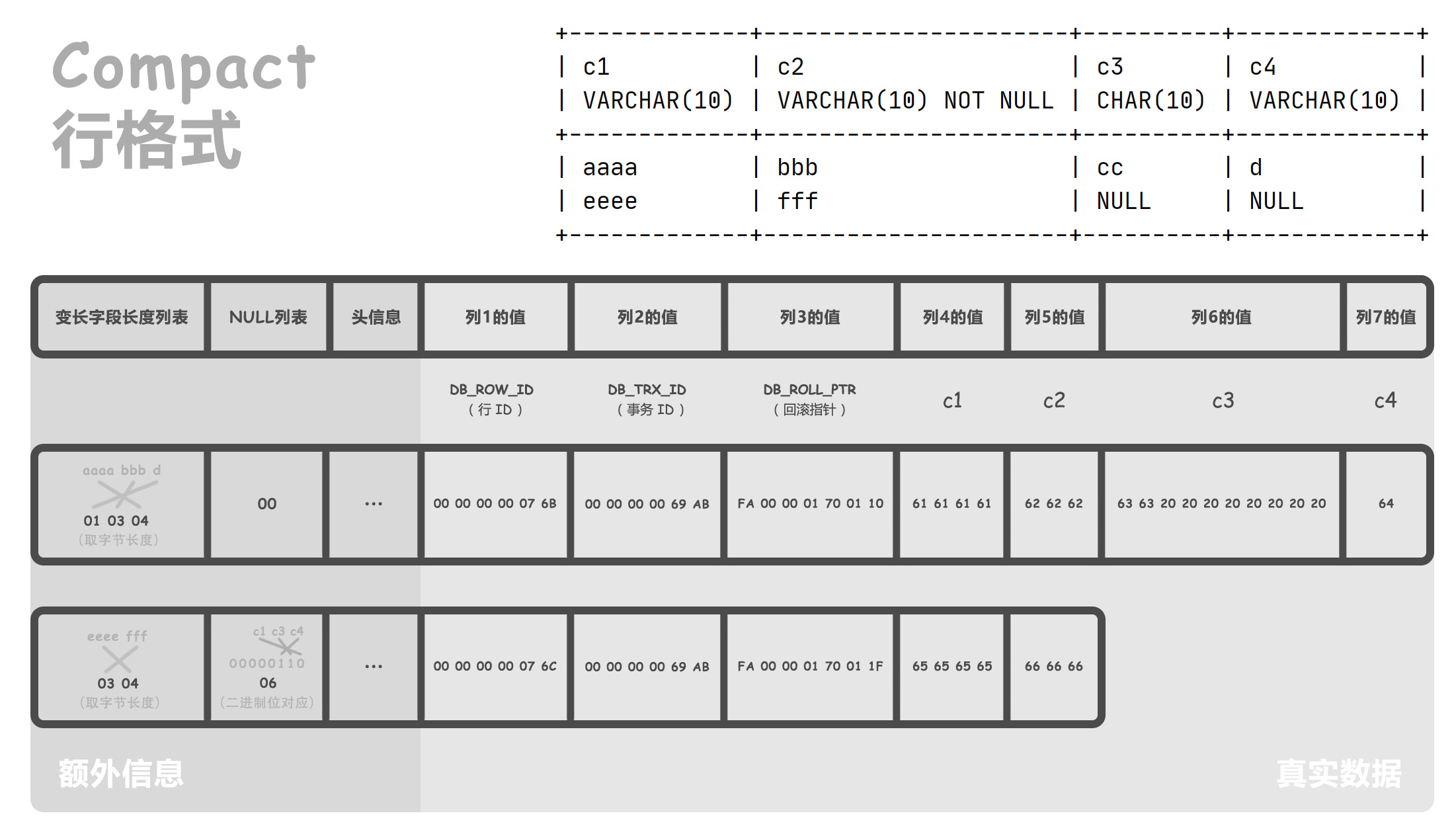
大致可以列出这些注意点:
CHAR(M)和VARCHAR(M)的 M 都是指最大字符长度,CHAR(M)固定长度,VARCHAR(M)可变长度。CHAR(10)存储 “aaa” 为 “aaa (补 7 个空格)”(空格在 ascii 中是 0x20)VARCHAR(10)存储 “aaa” 为 “aaa”- 顺便一提,以 utf-8 为例(1 个字符占 3 个字节),
CHAR(10)在 MySQL 5 之前占用 10 × 3 = 30 字节,在 MySQL 5 之后占用 10 - 30 字节,在节省空间和避免碎片之间做了平衡。
变长字段长度列表
- 所有非 NULL 的变长字段,字节长度,倒序排列
- 每个长度可能占 1 个字节(例如上图),也可能占 2 个字节
NULL 列表
- 可以不存在,如果该表的所有字段都不能为 NULL
- 允许为 NULL 的字段,是否为 NULL,倒序排序成 bitmap,补足整字节
头信息
共 5 字节,即 40 bit。
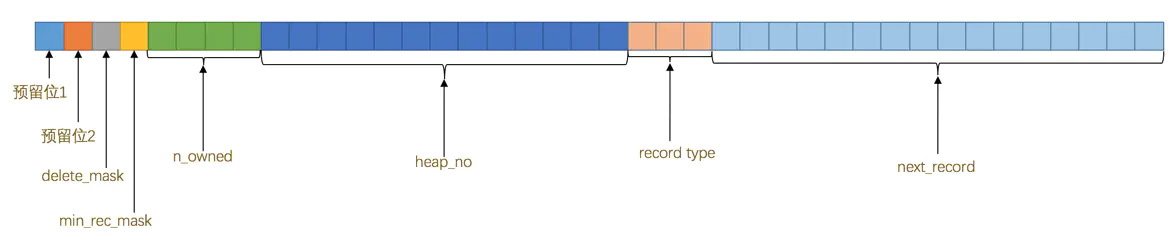
名称 大小(单位:bit) 描述 预留位1 1 没有使用 预留位2 1 没有使用 delete_mask 1 标记该记录是否被删除 min_rec_mask 1 B+树的每层非叶子节点中的最小记录都会添加该标记 n_owned 4 表示当前记录拥有的记录数 heap_no 13 表示当前记录在记录堆的位置信息 record_type 3 表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录 next_record 16 表示下一条记录的相对位置 真实数据
DB_ROW_ID不一定存在,如果存在就起到主键的作用。- 有主键就用主键
- 没有主键就选取一个
Unique键作为主键 - 都没有就添加一个隐藏键
DB_ROW_ID
DB_TRX_ID(事务 ID)和DB_ROLL_PTR(回滚指针)一定存在,意义后面有机会再说- 其他字段,如果非 NULL 才存在
页
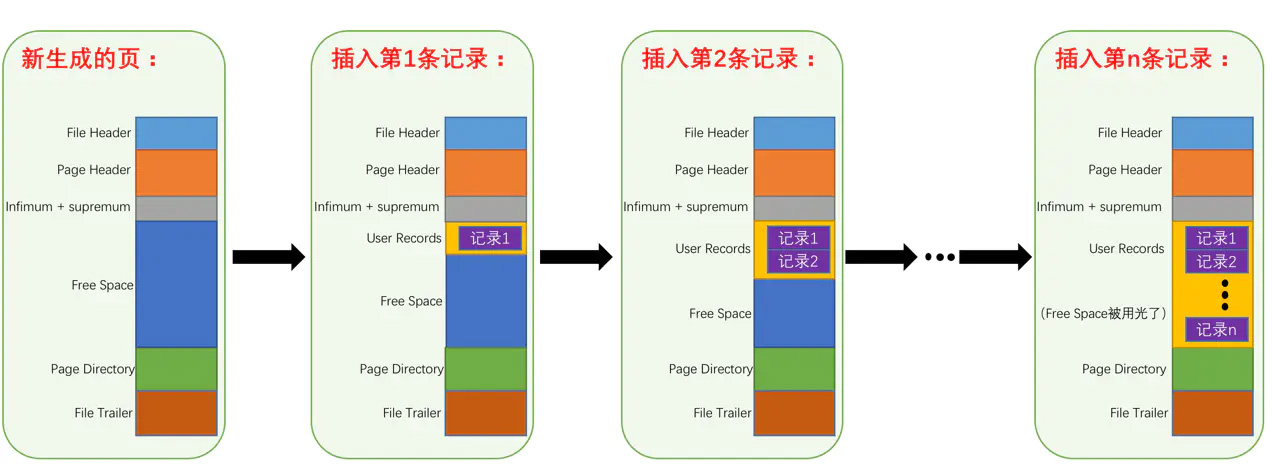
页的大小是固定的,每一页都是 16KB,页是装载行的容器,一页中有很多行(记录)。
页有很多的类型,比如表头页、日志页等,装载数据行的页是索引页(INDEX),我们以下说的内容都是索引页,下表是它的数据结构:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
| File Header | 文件头部 | 38字节 | 页的一些通用信息 |
| Page Header | 页面头部 | 56字节 | 数据页专有的一些信息 |
| Infimum + Supremum | 最小记录和最大记录 | 26字节 | 两个虚拟的行记录 |
| User Records | 用户记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页面目录 | 不确定 | 页中的某些记录的相对位置 |
| File Trailer | 文件尾部 | 8字节 | 校验页是否完整 |
File Header & File Trailer
所有类型的页,都有这两个部分的数据,也就是一页最上面的 File Header,以及一页最下面的 File Trailer。
File Header 是一页最开头的部分,它记录了页 ID、校验和、LSN 等内容:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| FIL_PAGE_SPACE_OR_CHKSUM | 4字节 | 页的校验和(checksum值) |
| FIL_PAGE_OFFSET | 4字节 | 页号 |
| FIL_PAGE_PREV | 4字节 | 上一个页的页号 |
| FIL_PAGE_NEXT | 4字节 | 下一个页的页号 |
| FIL_PAGE_LSN | 8字节 | 页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number) |
| FIL_PAGE_TYPE | 2字节 | 该页的类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8字节 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
| FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4字节 | 页属于哪个表空间 |
File Trailer 是一页最后的部分,它由两部分构成(各 4 字节,共 8 字节),前半部分是校验和,与 File Header 中的校验和相同,避免因磁盘加载问题导致数据错误,后半部分是 LSN,具体作用后面再说。
Page Header
索引页的 Page Header 部分,存储了本页存储了多少条记录、第一条记录的地址是多少等信息,比较复杂。
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2字节 | 在页目录中的槽数量 |
| PAGE_HEAP_TOP | 2字节 | 还未使用的空间最小地址,也就是说从该地址之后就是Free Space |
| PAGE_N_HEAP | 2字节 | 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) |
| PAGE_FREE | 2字节 | 第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) |
| PAGE_GARBAGE | 2字节 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2字节 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2字节 | 记录插入的方向 |
| PAGE_N_DIRECTION | 2字节 | 一个方向连续插入的记录数量 |
| PAGE_N_RECS | 2字节 | 该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) |
| PAGE_MAX_TRX_ID | 8字节 | 修改当前页的最大事务ID,该值仅在二级索引中定义 |
| PAGE_LEVEL | 2字节 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8字节 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
不是很重要,过吧。
Infimum & Supremum
最小记录和最大记录,具体作用需要理解记录的存储逻辑。
上一节画的行格式示意图,没有画出头信息,现在需要画出来这部分了(这是 Compact 行格式的头信息,其他行格式也差不多)。
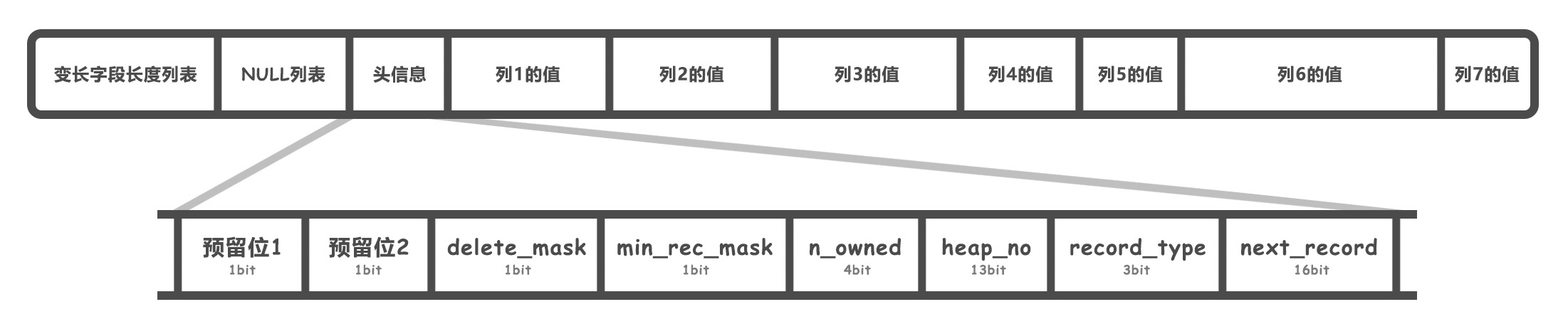
我们接下来要学习,多行数据是怎么逻辑相连的,这部分只跟行格式的头信息有关,因此在示意图上省略了其他信息:
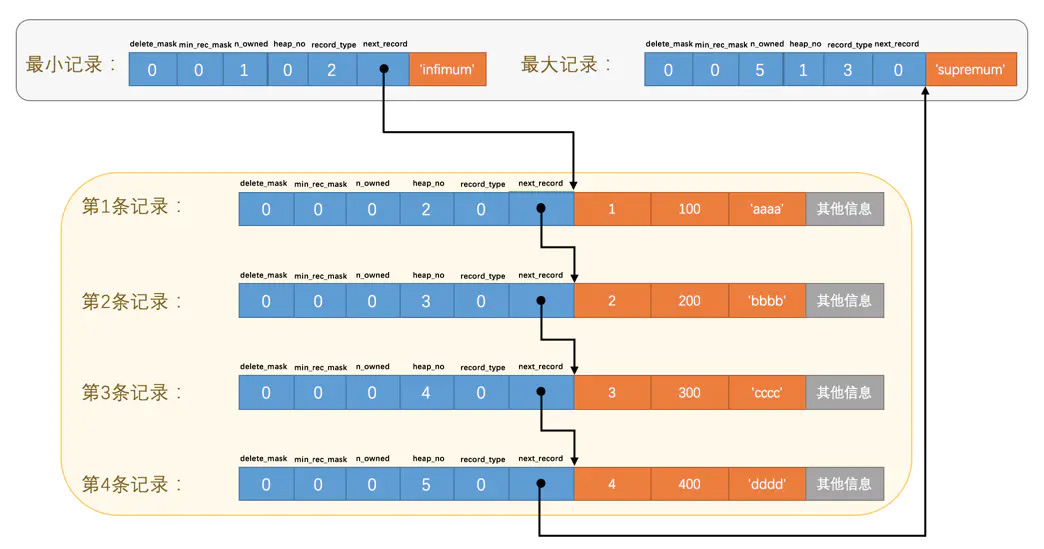
InnoDB 把多行数据做成链表的形式,创建页时会首先创建出链表头和链表尾,每多加一条数据,都会在链表中插入一条数据。(忽略了很多细节,比如一行数据太大怎么办,某一行怎么删掉,数据行太多一页装不下怎么办)
链表头是最小记录,由 5 字节的头信息和 8 字节的“Infimum”组成,链表尾是最大记录,由 5 字节的头信息和 8 字节的“Supremum”组成(当然,存储的都是二进制数据)。
再重新看一遍头信息的格式(Compact 行格式):
| 名称 | 大小(单位:bit) | 描述 |
|---|---|---|
| 预留位1 | 1 | 没有使用 |
| 预留位2 | 1 | 没有使用 |
| delete_mask | 1 | 标记该记录是否被删除 |
| min_rec_mask | 1 | B+树的每层非叶子节点中的最小记录都会添加该标记 |
| n_owned | 4 | 表示当前记录拥有的记录数 |
| heap_no | 13 | 表示当前记录在记录堆的位置信息 |
| record_type | 3 | 表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录 |
| next_record | 16 | 表示下一条记录的相对位置 |
User Records & Free Space
这部分就是每页存储数据的地方。
已经存储数据行的部分,叫做 User Records,还没使用的部分,叫做 Free Space。结合最开始的页示意图,很容易看懂。
Page Directory
一页有 16 KB 的大小,可以放很多很多行数据(具体能放多少条,跟每行数据有多少个字段相关)。
链表的搜索效率的 O(n),如果数据量很大,那么查询速度会非常慢。因此 InnoDB 又提出了 页目录(Page Directory)的概念,将搜索效率提高到 O(logn)。
逻辑是这样的:
- 链表需要按照主键的大小排序(如果没有主键,就使用
Unique键,再没有就生成一个隐藏键DB_ROW_ID) - 链表每几个节点分一个组,把每组最后的链表节点的地址,记录在 Page Directory 里(相当于记录在一个数组里)
这样就能通过二分检索数组,将搜索效率提高到 O(logn) 了。下图是示意图,最左侧就是 Page Directory:
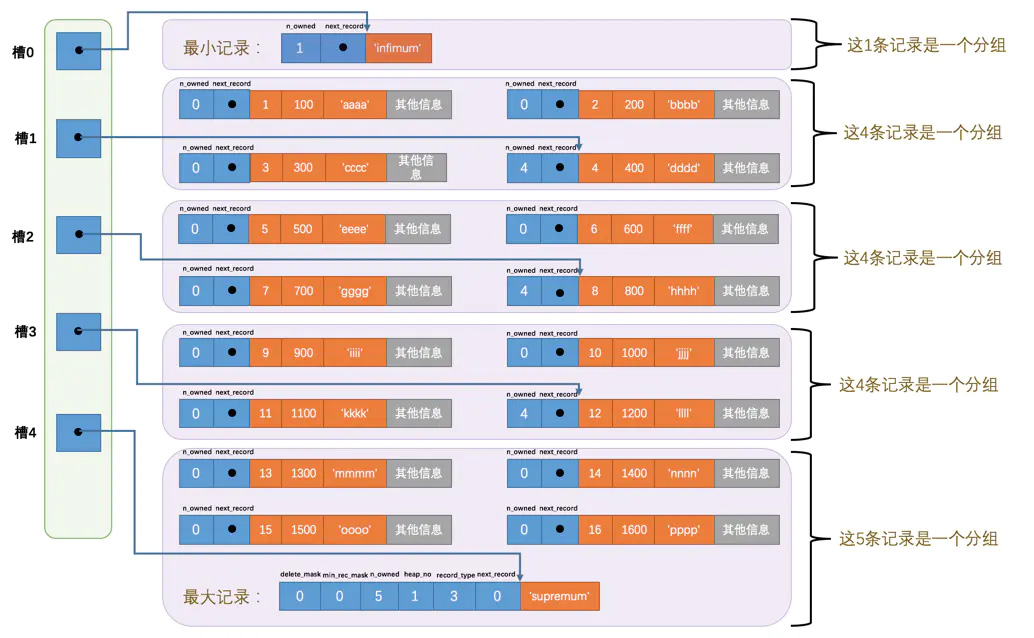
补充几个细节:
- 头信息中的
n_owned字段,代表分组后本组有多少行数据,只有每组最后的一个链表节点有这个数据。 - 每一组最多 8 行数据(最小记录只有自己 1 行,最大记录允许 1-8 行,其他组 4-8 行)。
二分法查找主键的过程不写了。
表空间 & 组 & 区
这部分的概念非常多,但是感觉偏向具体实现,对理解 InnoDB 帮助没有那么大,因此简略写写就过了。
表空间
表空间是 InnoDB 中最大的概念,最大可以 64TB(因为页号最大 2^32,单页 16KB,总共最多 64TB)。
有很多种表空间,比如系统表空间、独立表空间、临时表空间等。在如今的 MySQL 版本中,表数据基本都存储在独立表空间当中(为每一个表建立一个独立表空间)。
组
表空间由组构成,每个组 256MB(2^14 页)。
表空间的第一个组,头三个页是固定的,其他组的头两个页是固定的。
第一个组的前三个页面分别是 FSP_HDR 页、IBUF_BITMAP 页,INODE 页:
FSP_HDR页:这是整个表空间的第一个页,记录了整个表空间的信息,以及本组的区信息(区的概念下面说)IBUF_BITMAP页:本组关于INSERT BUFFER的信息(这个后面的文章说)INODE页:本组的段信息(段的概念下面说)
其他组的前两个页面分别是 XDES 页、IBUF_BITMAP 页:
XDES页:本组的区信息IBUF_BITMAP页:本组关于INSERT BUFFER的信息
我感觉这些都不是很重要,只需要知道每个组会把一些统计信息单独抽出几个页出来,放在最前面。
区
由于组还是太大了,管理页不方便,因此还有区(extent)的概念,一个区 1MB(64 页)。
引入区的概念,主要还是增加读写速度。InnoDB 的数据是以链表的形式存储的,链表可以东存一块,西存一块。但是对于存储系统来说,随机读写的速度要远低于顺序读写,如果内存是连续的,读写速度会大幅提升。因此如果把数据存到连续的磁盘区域,能提高很多速度。
因此 InnoDB 一次申请一个区的磁盘空间(1 MB,64 个页),浪费一点空间,但是消除很多随机读写,提高性能。但是如果数据量很小,直接申请一个区的空间显得很浪费,因此有碎片区的概念,不同的表都可以使用同一个碎片区,新插入数据先使用碎片区的页,超过 32 页之后再单独创建区。
段
上面所说的都是物理空间,有固定的大小,段(Segment)是逻辑上的空间,没有固定大小。段由一些零散的页面以及一些固定的区构成。
接下来要说的内容是下一篇文章的主题,就是 InnoDB 是怎么存储索引的。每个索引在 InnoDB 中都是一棵 B+ 树,按照索引值的大小排序,因此可以达到 O(logn) 的查询效率。这棵二叉树的叶子节点(最下面一层)和非叶子节点,数据结构是不相同的,查询逻辑也是不相同的,因此把这两部分存储在不同的区域。
存放叶子节点的存储区域,被称为一个段,存放非叶子节点的存储区域,被称为另一个段。也就是说每个索引在存储时,默认会出现两个段,这两个段使用不同的存储区域。