Redis 数据结构
十一月的第三周,入门 Redis,从数据结构开始。
Redis 是一个基于内存的高性能 key-value 数据库。
Redis 有五种数据结构(准确说应该是数据结构类),分别是 String(字符串)、List(列表)、Hash(哈希表)、Set(集合)、ZSet(有序集合)。这五种对象在 Java 中都有(ZSet 就是 SortedSet),很容易理解。
Redis 是 key-value 型数据库,所谓有五种数据结构,意思是 value 有五种,但 key 始终都是字符串。一个单数据库的 Redis 可以视为一张大的 HashMap,这个 HashMap 的 key 始终都是一个字符串,而 value 可以是 String、List、Hash、Set、ZSet。
对于 Redis 的使用者而言,只会看到五种数据结构,但是 Redis 内部其实还有编码和内部数据结构,比如说 Redis 在存储 "hello world" 和 "helloooooooooooooooooooooooooooooo world" 这两个字符串时,底层的实现是不一样的。Redis 内部有六种数据结构,通过不同的组合方式,对外暴露了五种封装过的数据结构,组合方式如下图所示:
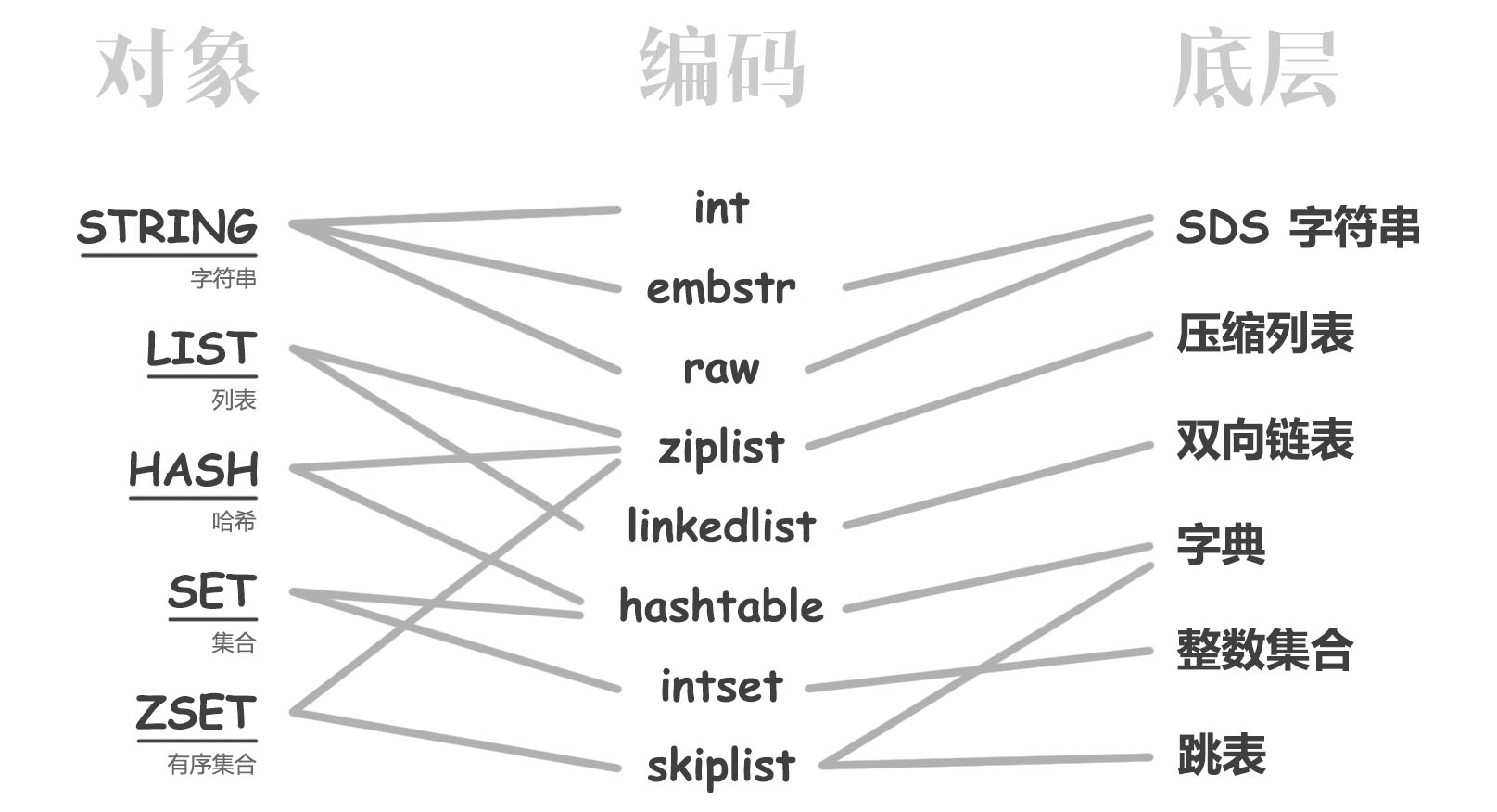
我们分两部分来看,首先看底层的数据结构,然后看封装过的对象。
Redis 的底层一共有六种数据结构,除了跳表之外的五种数据结构都很容易理解,Redis 是用 C 写的,因此本来也就写不出什么复杂的东西hhh,下面一个个看吧。
下面的所有内容和图片,基本都来源自《Redis 设计与实现》一书,该书基于 Redis 3.0 编写,好多好多好多内容都已经变了,看个大概吧。
SDS 字符串
SDS 字符串即简单动态字符串(simple dynamic string, SDS),是一种类似 ArrayList 的数据结构。
SDS 在 Redis 中定义为 sdshdr 类,它有几个内部属性:
1 | struct sdshdr { |
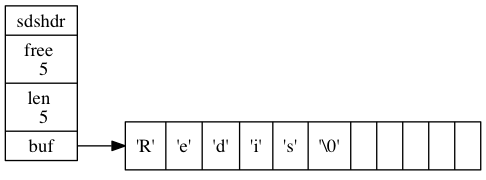
以上图为例,存储了一个 “Redis” 字符串,len = 5(使用了 5 字节,不算入 ‘\0’ 字符),free = 5(还有 5 字节可用),buf 是一个字符数组。
SDS 字符串长度不足时会进行扩容
- 如果扩容后的 len 小于 1 MB,扩容后预留多一倍的长度(len == free)
- 如果扩容后的 len 大于等于 1 MB,扩容后将多预留 1 MB 的长度(free == 1MB)
SDS 字符串缩短时,不会立即处理,未来有需要时再释放内存。
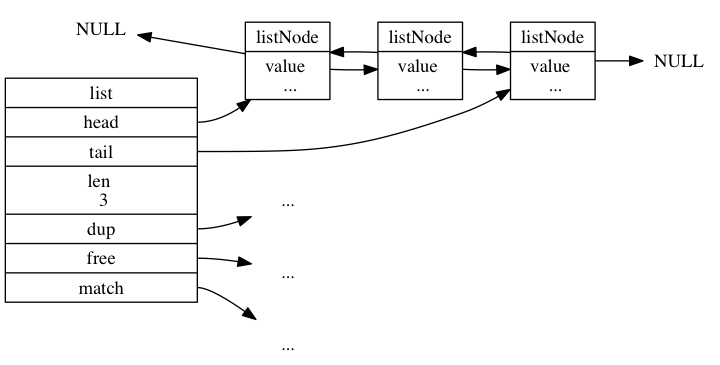
双向链表
跟 LinkedList 的核心设计差不多,没什么可说的,贴一下代码和图片,过了。
1 | /** |
字典
字典就是 Map,Redis 的实现跟 HashMap 相同。
哈希算法采用 MurmurHash2 算法,处理哈希冲突的方式是拉链法,数据结构跟 HashMap 别无二致,代码和图都不贴了。
扩容要单独说一下。
Redis 的字典扩容时,会创建一个新的数组,新数据插到新数组里,老数据逐步迁过来,当老数组搬空了之后,新数组替代老数组,扩容结束。具体有下面这几个细节:
扩容后的大小,是大于等于原键值对数量两倍的 2^n,比如原数组的键值对有 100 个,那么扩容后数组的长度是 100 * 2 = 200 -> 256。
扩容不是一次性完成的,而是一点点完成的。
每次进行查询、新增、更新、删除操作时,会把老数组在下标
rehashidx上的所有键值对,都拷贝到新数组上。rehashidx从 0 开始,每查询、新增、更新、删除一次,拷贝一次,数值增加 1,直到遍历完老数组的数组长度。扩容过程中的查询、更新、删除会在两个数组上执行,新增只在新数组上执行。
扩容的条件:
- 服务器没有执行 BGSAVE 或 BGREWRITEAOP 命令时,负载因子 >= 1
- 服务器没有执行 BGSAVE 或 BGREWRITEAOP 命令时,负载因子 >= 5
Redis 的字典也会收缩,在负载因子 < 0.1 时执行收缩,大小是原键值对数量的 2^n,其他跟扩容一样。
跳表
跳表是我第一次见的数据结构,查了一下可以近似等效为红黑树,查询、插入、删除的效率都是 O(log n) 。这种数据结构的优势是实现起来简单。
跳表的数据结构大致长这样(下图来源自《跳表──没听过但很犀利的数据结构》):

这种数据结构看得我挺头疼的,查了一下只应用在 Redis 和几个我没听说过的工具上使用,暂且放过了。
Redis 使用跳表而不使用红黑树的原因,一是实现简单,二是可以实现区间查询(比如在 [100, 200] 中查询数据,而红黑树实现起来很麻烦),更多的原因可以参考《为啥 redis 使用跳表(skiplist)而不是使用 red-black?》。
整数集合
整数集合可以视为一个排序后的 int 数组,长度固定。所以如果要新增或删除元素,就要有 O(n) 的时间复杂度(查询可以用二分查找,时间复杂度 O(log n))。
1 | typedef struct intset { |
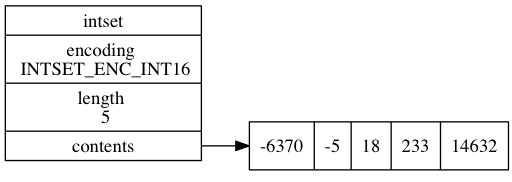
整数集合只使用在元素数量较少时(小于 512 个)时的 SET 对象中,因为插入和删除的时间代价有点大,但是很省空间。
压缩列表
压缩列表为了省内存而生,底层数据结构就是一块连续的内存空间,插入或删除的时间代价很大,但很省内存。
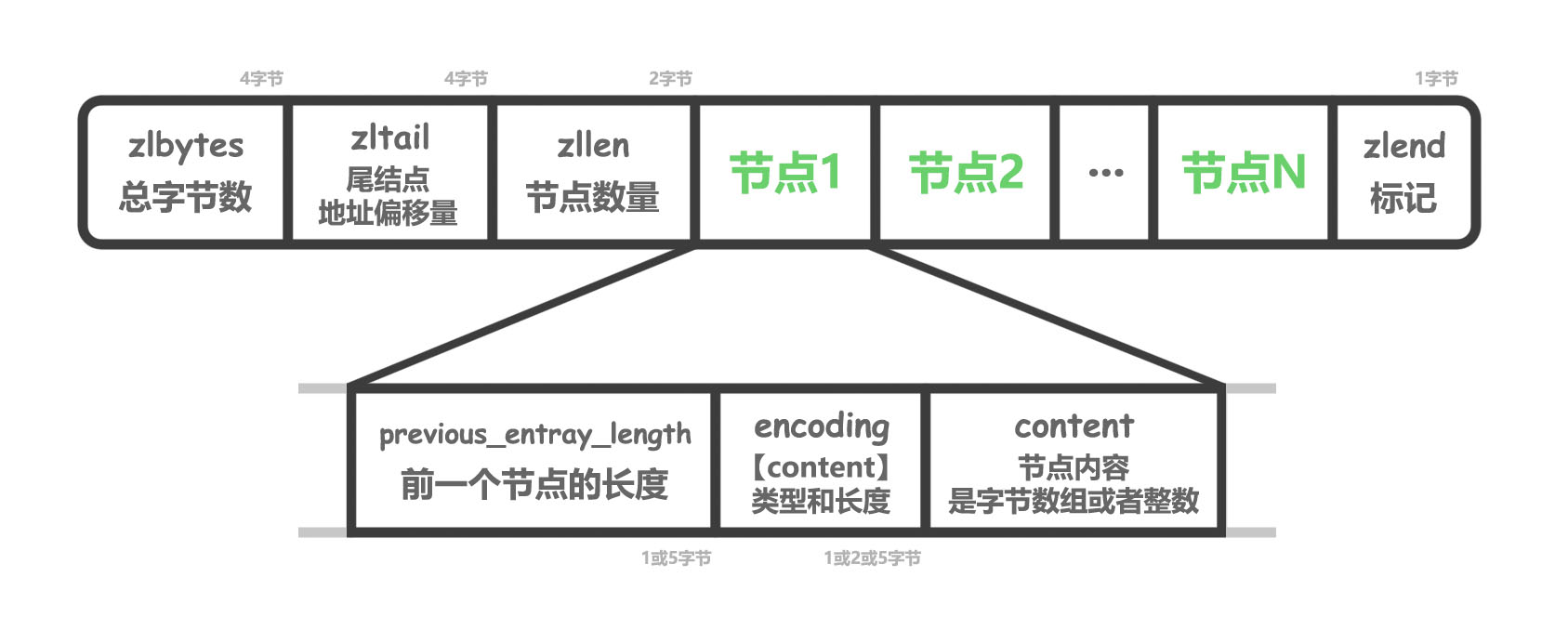
压缩列表的每个节点,可以存储一个数字,或者一个字节数组,具体存储的内容由 encoding 字段决定。
压缩列表可以实现正序遍历和倒序遍历,查询效率是 O(n),新增和删除效率平均 O(n),最差 O(n^2)(但是很难最差),总之效率是很差,但是很省空间,对于 Redis 这种内存型数据库,空间还是能省一点是一点。
看完六种底层数据结构,可以学习对外暴露的五种数据结构了。
Redis 的数据结构对象,有编码(encoding)的概念,同一种数据结构,在不同的情况下,可以有不同的编码,以应对不同的场景。通常数据量小时会选择省内存的编码,数据量大时会选择省时间的编码。
STRING 字符串
Redis 的字符串对象,跟通常意义上的字符串不太一样,数字在 Redis 也是一个字符串对象。
Redis 的字符串对象有三种(对应三种编码),分别是:
- 数字字符串(编码:int)
- 短字符串(编码:embstr)
- 长字符串(编码:raw)
int 类编码把数字直接存储在对象中,而 embstr 和 raw 编码都使用 SDS 作为底层的数据结构,不同的是 embstr 字符串比较短,申请 SDS 的空间时和字符串自己的空间一起申请,而 raw 字符串比较长,单独申请 SDS 的空间,再用指针指过去。
raw 和 embstr 的编码区别如下图所示:
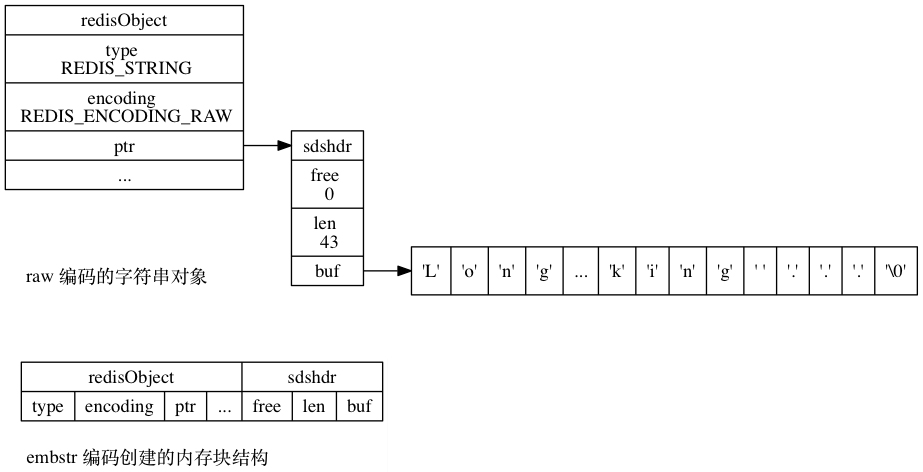
当字符串长度小于 39 字节时(由于 SDS 字符串数据结构的改进,现在提升到 44 字节了),会使用 embstr 编码,当字符串长度大于 39 字节时,会使用 raw 编码。
39 字节的来源是这样的,字符串对象本身占 16 字节,SDS 对象 free 和 len 属性各占 4 字节,字符串以 ‘\0’ 字符结尾还要再占 1 字节,加起来一算,16 + 4 + 4 + 1 + 39 = 64,刚好是 CPU 在 64 位机器上一次寻址的字节长度。(如今 free 和 len 可以只占 3 字节,因此多省出来 5 个字节,变成以 44 字节为界,具体可参考《Redis 的 embstr 与 raw 编码方式不再以 39 字节为界了!》)
总结一下:
- 如果存储 long 类型的整数,使用 int 编码
- 如果存储 39 字节及以内的字符串,使用 embstr 编码,底层是 SDS
- 如果存储 39 字节以上的字符串,使用 raw 编码,底层是 SDS(如果 embstr 编码的字符串发生改变,即使长度不到 39 字节,也会转为 raw 编码)
LIST 列表
列表对象有两种编码,分别是 ziplist 编码(压缩列表)和 linkedlist 编码(双向链表)。
当列表的长度小于 512,且每个元素的长度小于 64 字节时,使用 ziplist 编码,否则使用 linkedlist 编码。
HASH 哈希
哈希对象有两种编码,分别是 ziplist 编码(压缩列表)和 hashtable 编码(哈希表)。
使用压缩列表的话,会把 key 和 value 作为两个节点,加入到压缩列表的内部。
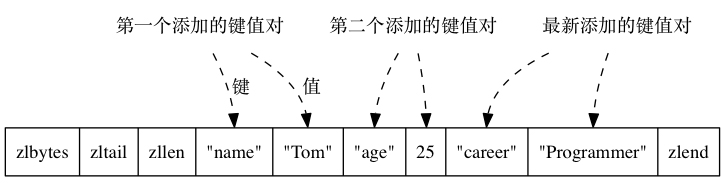
当哈希对象的 key-value 对少于 512 个,且 key 和 value 的长度都小于 64 字节时,使用 ziplist 编码,否则使用 linkedlist 编码。
SET 集合
集合对象有两种编码,分别是 intset (整数集合)编码和 hashtable 编码(哈希表)。
当集合对象的每个元素都是整数,且个数少于 512 个时,使用 intset 编码,否则使用 hashtable 编码。
ZSET 有序集合
有序集合有点像 SortedSet,意思是可以给每个元素设定权重,内部按照权重顺序存储,比如:
1 | ZADD price 8.5 apple 5.0 banana 6.0 cherry |
有序集合对象有两种编码,分别是 ziplist 编码(压缩列表)和 skiplist 编码(跳表+哈希表)。
使用 ziplist(压缩列表)的话,会把元素和权重值作为两个节点,加入到压缩列表的内部。
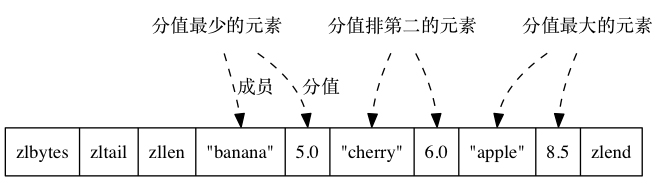
使用 skiplist 的话,底层会同时使用跳表和哈希表这两种数据结构,ZRANK、ZRANGE 这类范围型操作使用跳表(可以保证顺序),根据元素查找权重这类操作使用哈希表(可以保证 O(1) 的时间复杂度)。
当有序集合对象的元素数量小于 128 个,且每个元素的长度小于 64 字节时,使用 ziplist 编码,否则使用 skiplist 编码。
这周就先看这么点。