ThreadLocal
七月的第一周,来学习 ThreadLocal。
半年前我完全看不懂这个类,现在已经能看懂了。这几天刚开始看源码时,觉得这是个很精巧的小设计,后来又找资料,发现里面的知识很深,没我想的那么简单。
我在学习 ThreadLocal 时,看到两个很好视频,安利一下。一个是《【java】什么是ThreadLocal?》(短小紧凑,科普向,但是结尾有关弱引用的结论是错的,瑕不掩瑜,记得看评论区),另一个是《只有马士兵老师能把ThreadLocal底层原理、内存泄漏分析的这么测透》(马士兵老师讲的,比较长,但是非常出色,看得我很 high)。
ThreadLocal 类与线程局部存储(Thread Local Storage, TLS)的概念有关,意思是说对象是线程独有的:
维基:对象的存储是在线程开始时分配,线程结束时回收,每个线程有该对象自己的实例。
可以把 ThreadLocal 视为一个普通变量,他与普通的变量之间的区别在于,ThreadLocal 变量只属于某个线程。
1 | String word1; |
例如上面的代码,声明了两个变量 word1 和 word2。这两个变量在使用时都是字符串,也都声明成是”pz”,但是前者 word1 在任何情况下都能获得,后者只有为它赋值的线程能获得,其他的线程都不能获得:
1 | // 对于刚才赋值的线程而言,s是"pz",对于其他线程,s是null |
线程局部存储,可以让某些信息在同一个线程中,实现上下文数据共享,比如一个线程先后执行多个方法,每个方法都需要 User 信息,那么可以定义一个 ThreadLocal<User>,每个线程都能获取到各自的 User。
再举一个应对面试的 Spring 应用实例,在事务管理时(@Transactional),Spring 会把数据库连接或者 hibernate session 存储在 ThreadLocal 中,这样就可以在各个方法查询各张表时实现事务控制。
基本原理
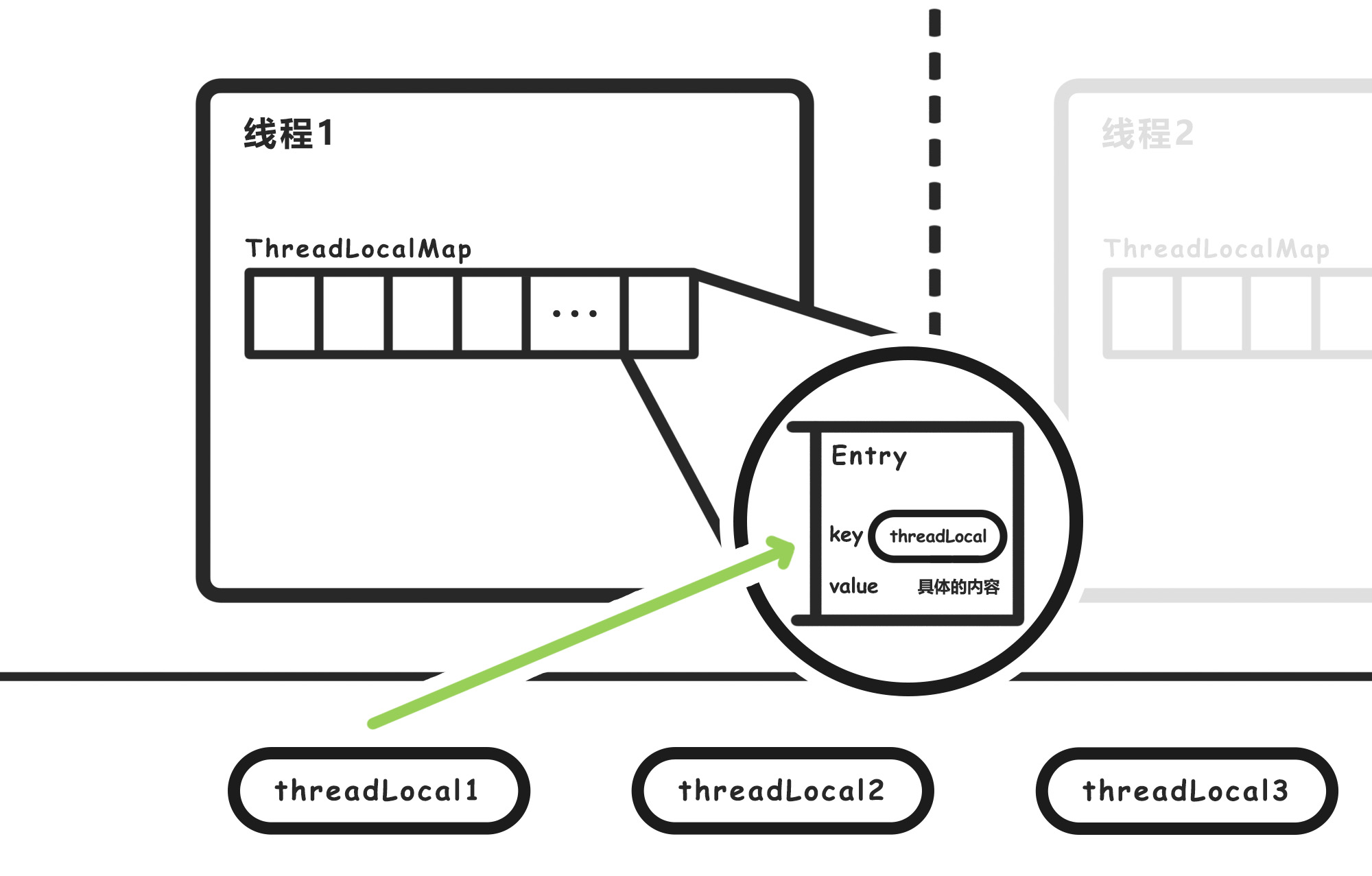
ThreadLocal 的实现原理,是让每个线程自己维护一张 map,key 是 threadLocal 对象,value 是实际想存储的内容。
每个线程拿着 ThreadLocal 对象,把它作为 key,去自己独有的 map 里找到 key 对应的 value,由此实现了线程局部存储。
直接来看 get() 方法:
1 | public T get() { |
基本逻辑很简单,获取当前线程,根据当前线程获取 map,在 map 里根据 ThreadLocal 对象找 entry,返回 entry 的 value。
在这个主要流程里,我们还需要去扒:
- 怎么根据当前线程获取 map
- 怎么在 map 里根据 ThreadLocal 找到 entry
第一个问题特别简单,map 就是 Thread 的一个成员变量,直接返回:
1 | ThreadLocalMap getMap(Thread t) { |
第二个问题有点难,涉及到 map 的数据结构。
先提一下 map 具体是什么,这里的 map 实际上就是一个数组(没有链表),这个数组里的每一个元素都是一个 Entry:
1 | static class ThreadLocalMap { |
Entry 涉及到弱引用,这个后面再提,先看怎么从 map 中找到 entry:
1 | private Entry getEntry(ThreadLocal<?> key) { |
从整体上讲,这个 map 采用开放定址法,而不是拉链法,来解决哈希碰撞问题。
这种算法的大致原理是,计算出哈希值,然后存入数组里相应的位置,如果这个位置已经存在元素了(哈希碰撞),那么查看下一个数组格子是否是空的,一直找,直到找到一个空的位置,然后存进去。取的时候也是一样,先计算出哈希值,然后找相应数组下标内的元素,如果 key 对上了就是,如果对不上,找下一个。
关于使用开放定址法,存在两个疑问:为什么要使用它,而不是使用像 HashMap 一样的拉链法?使用这种需要优化什么?
第一个问题涉及到弱引用,这个后面再提。
第二个问题其实是在思考开放定址法的问题:如果每次计算出来的数组下标,距离靠得很近,那如果发生哈希碰撞,这个不对,找下一个,还不对,再找下一个,岂不是要找死?所以要让计算出来的数组下标,要分布尽可能地均匀。
特殊的 hash 算法
ThreadLocal 计算数组,是通过内部的一个数字计算的,这个数字很奇特,每个 ThreadLocal 的数字都不一样,但是它们都是一个公共数字 HASH_INCREMENT 的整数倍(会溢出,但是无所谓)。在程序启动之后,出现的第一个 ThreadLocal 对象内部的数字是 HASH_INCREMENT 的一倍,第二个 ThreadLocal 对象内部的数字是 HASH_INCREMENT 的两倍,以此类推,第 n 个 ThreadLocal 对象内部的数字是 HASH_INCREMENT 的 n 倍。
每个 ThreadLocal 对象内部的那个数字是 threadLocalHashCode(见名知意,就是 hash 值),而以 HASH_INCREMENT 为基的这个数字,大小初看很奇怪:
1 | private static final int HASH_INCREMENT = 0x61c88647; |
这个数字用十进制表示是 1640531527,它是 2^32 的黄金分割数,也就是 (2^32)/0.618。使用这个数字的整数倍,能计算得出很均匀的 map 下标(前提 map 的长度是 2 的幂)。具体的计算步骤是,获取 ThreadLocal 内部的那个数字(threadLocalHashCode),然后对 map 的长度 -1 取模,计算出一个不超过 map 长度的数字,这个数字就是数组的下标。
举个例子,0 - 31 这 32 个数字分别与 0x61c88647 相乘,然后再对 31 (0b11111)取模,依旧能获得 32 个不同的数字:
1 | int HASH_INCREMENT = 0x61c88647; |
当数组长度是 2 的幂时,都可以做到如此均匀,虽然我不知道为什么(试着找了一些文章,但是看不懂hhh),但是觉得好牛x啊。
下图来源自文章《Fibonacci Hashing》,感受一下分布均匀度。
有关 ThreadLocal 的 hash 算法就写到这里,然后我们来看 map 中的每一个元素:Entry。
Entry 与弱引用
这是 Entry 的源码:
1 | static class Entry extends WeakReference<ThreadLocal<?>> { |
它实际上就是 key-value 键值对,跟其他任何 map 里的设计都是一样的,有 key,也有 value。
它的 key,是 ThreadLocal 对象(尽管看源码有点懵),它的 value,就是线程局部存储的值,例如下面这两行代码:
1 | ThreadLocal<String> threadLocal = new ThreadLocal<>(); |
执行 set 方法的那个线程,它内部的 map 里的某一个格子,就是一个 Entry,这个 Entry 的 key 就是 threadlocal 对象,它的 value 是 “pz”。
Entry 源码里面看到了 value,但是没有看到 key,key 是通过 WeakReference(弱引用)来实现的。
弱引用是 JDK 1.2 出现的,这个概念跟 Java 虚拟机有关。弱引用是引用的一种,引用总共有四种,,我简单列一下:
- 强引用(Strong Reference):正常引用,根据垃圾回收算法,当这个引用存在时,就无法对引用对象进行 GC(如果根可达的话)
- 软引用(Soft Reference):能够获取到引用对象,当发生 FGC 时,会回收引用对象,应用在缓存等。
- 弱引用(Weak Reference):能够获取到引用对象,当发生 GC 时,会回收引用对象,应用在 ThreadLocal 等。
- 虚引用(Phantom Reference):不能获取到引用对象,作用是当引用对象被 GC 时,虚引用会获得一个系统通知,应用场景跟一般的代码无关。
上面写的引用,我只是简单一写,想理解的话去看《深入理解 Java 虚拟机》讲垃圾回收的部分,或是最开始提到的马士兵老师的视频,都讲得很好。
话说回来,继续看弱引用,看下面这两行代码:
1 | WeakReference<String> r = new WeakReference<>("pz"); |
上面创建了一个弱引用 WeakReference 对象 r,它引用到了一个字符串 “pz”,如果没有发生垃圾回收,那么可以通过 r.get() 方法获取到 “pz”,但如果发生了垃圾回收,这个虚引用并不会影响到字符串 “pz” 的回收,如果它真被回收了,那么执行 r.get() 方法将会获得 null。
因此再回去看 Entry 源码,发现 Entry 继承自 WeakReference,它可以通过虚引用获取到 ThreadLocal 对象,比如创建一个 Entry 对象(当然由于 private,下面的代码是实现不了的hh):
1 | Entry entry = new Entry(threadLocal, "pz"); |
如此可以看出,Entry 实际上就是 key-value 键值对,从 hash 开放定址法上来说,应该是没问题了,逻辑闭环了,但是有另一个问题:为什么要使用弱引用?
这主要与垃圾回收有关:如果 Entry 通过正常的引用关联 ThreadLocal 对象,那么如果线程不死,map 不清,由于强引用关系,ThreadLocal 对象就永远也不能被垃圾回收,这样即使某些 ThreadLocal 用不上了,它仍然不会被清理掉,造成内存泄漏。
(这里我还是有点疑惑,真的有这种内存泄漏的场景吗)
本来还想学点数据库事务的 ThreadLocal 原理的,但是写了这么多字懒了,告辞。