ConcurrentHashMap
本篇着重学习 JDK 8 的ConcurrentHashMap,对于 JKD 7 的设计也顺便学习一下。
学习来源基本上源自博文《Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析》,这篇文章已经写得非常不错了,就是无奈道格李的代码太难读了,因此还是要很认真地学习才能看懂。
首先简单提一下 JDK 7 时的 ConcurrentHashMap 的设计(下图来自前面提到的博文)。
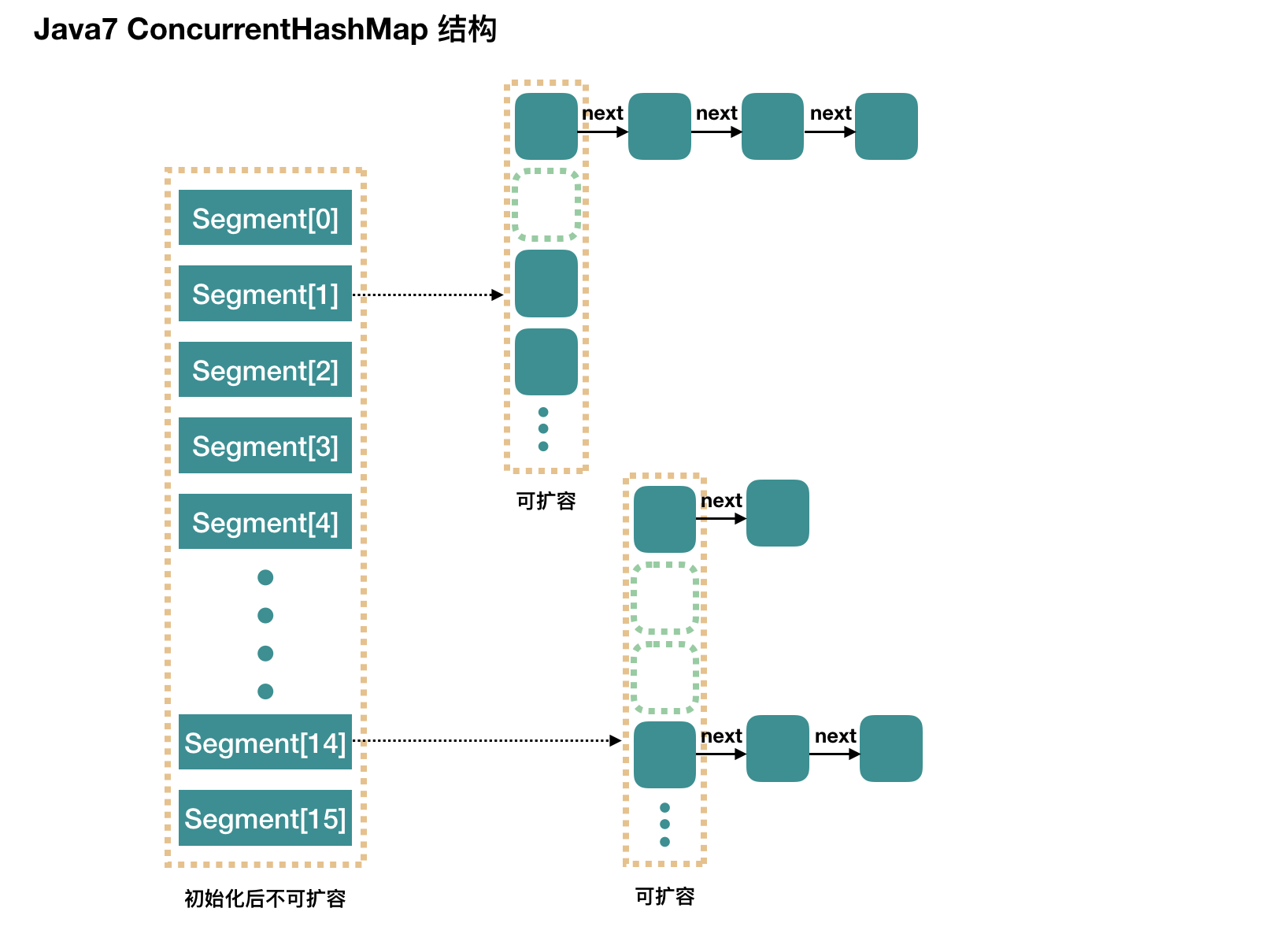
JDK 7 时 ConcurrentHashMap 采用分段锁的设计,维护一个 Segment 数组,每个 Segment 都是一个锁(继承自 ReentrantLock),该 Segment 内部有一个可扩容数组(同 HashMap 的设计)用于真正存储元素。相比于 Hashtable 对整个方法加 synchronized 锁,ConcurrentHashMap 对 Segment 上锁,相当于降低了锁的颗粒度,提高了性能。
不看源码了,只写一点实现细节吧:
Segment 数组初始化后不可扩容,默认是 16 个 Segment,可通过构造方法改变初值(初值会自动上抬为 2 的幂数,构造方法与 HashMap 有不同)。
存储元素时分段存储,算法是取 hash 的高位(如果 Segment 数组长度是 16,那么就取 hash 的高 4 位),然后算出存储在哪个 Segment。比如 hash 高 4 位是 1010,那么存储在 Segment[10],如果 hash 高 4 位是 0011,那么存储在 Segment[3]。
1
2// 当有16个Segment时,hash无符号右移28位(剩下高4位),然后与操作15,得出存储的Segment的位置
int j = (hash >>> segmentShift) & segmentMask;(看到这里你应该明白,为什么 Segment 的个数也需要是 2 的幂数了)
Segment 内部由数组+链表组成(跟 HashMap 的原理相同,拉链法),链表采用尾插法。存 entry 前先获取 Segment 的锁,在保证持有锁的前提下存储 entry。
构造方法初始化时,会创建 Segment 数组,并只会创建出第 0 个 Segment:Segment[0],Segment[0] 内部的数组长度初值为 2,根据负载因子扩容(默认 0.75),这样插入第一个元素不扩容,插入第二个元素才扩容。其他 Segment[i] 会在存储 entry 时再创建,数组长度和负载因子同当时的 Segment[0](有可能 Segment[0] 扩容过,那么就使用扩容之后 Segment[0] 的长度)。
ConcurrentHashMap 的 get() 方法没有做任何并发处理,主要是依赖于 volatile 关键字配合 UNSAFE 包实现读取时的数据一致(具体原理略)。
JDK 8 的 ConcurrentHashMap 放弃了 Segment 分段锁的设计,转而使用跟 HashMap 相同的数据结构,但是实现上考虑并发。
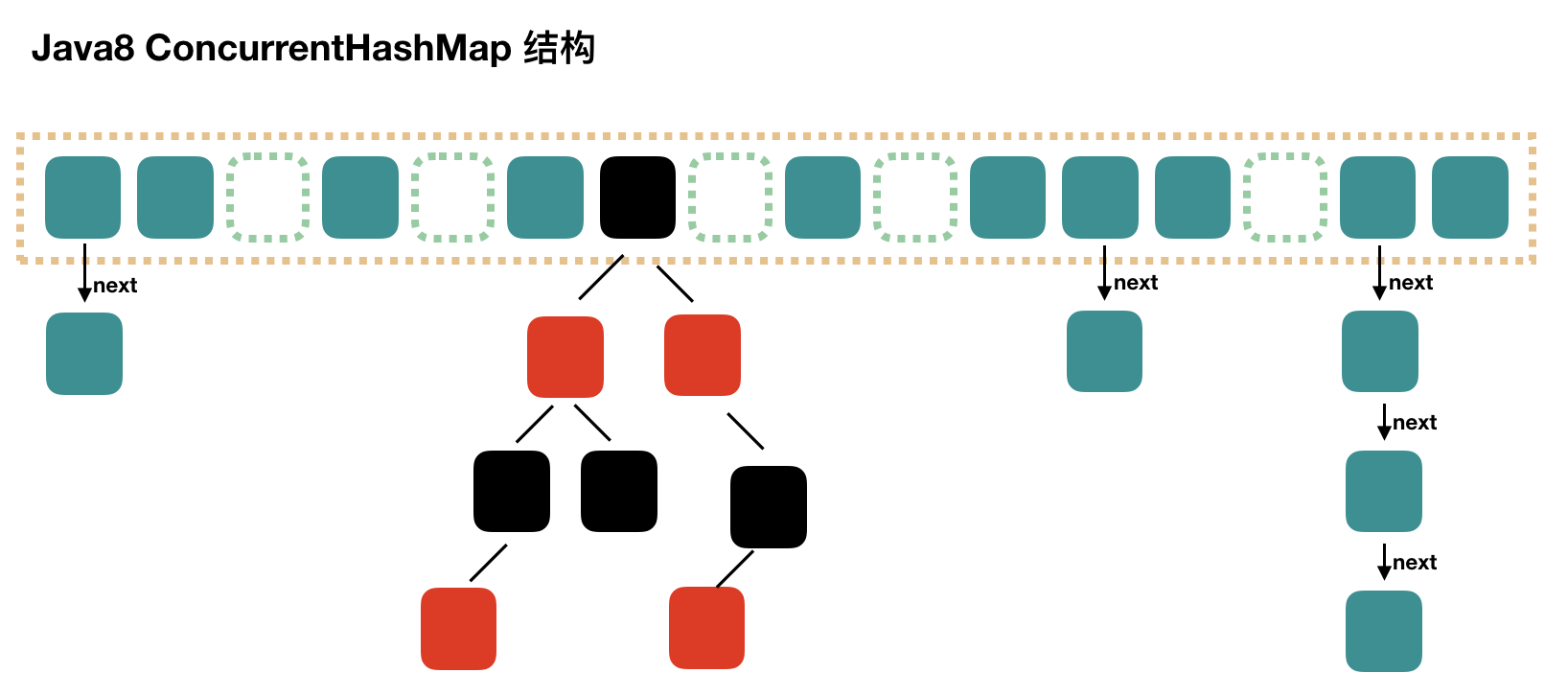
推测一下放弃分段锁的原因:
原先采取 Segment 分段,默认情况下最多分 16 段,而 Segment 是通过继承 ReentrantLock 实现的,这就意味着可能同一时间需要维护 16 个 AQS 队列,对内存的消耗还是比较大的。
如果联想下 HashMap,同一时间不太会有多个线程对同一个数组格子进行编辑,那么可以使用 synchronized 修饰每一个格子,锁的优化让 JVM 去处理。
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { | |
源码点到为止(真不喜欢看道格李的代码= =),一些实现细节列在下面:
ConcurrentHashMap 的 key 和 value 都不支持 null 值,这点跟 HashTable 一致,但是 HashMap 是支持的(key 和 value 都支持)。
关于这点我曾在分析 HashTable 的源码时提过,明面上的原因是:如果 value 允许 null,那么当
map.get(...) == null时,不能知道返回的 null 是代表 value 为 null,还是说根本没有 key,对于 HashMap 单线程可以使用 containsKey() 方法判断,但是多线程并发的 ConcurrentHashMap 和 HashTable 是判断不出来的。还有一层原因是,道格李不希望在 Map 和 Set 容器中支持 null,他认为这是定时炸弹。有关这个问题可以参考该网站:道格李对 ConcurrentHashMap 不支持 null 的解释
在 JDK8 的代码实现中,ConcurrentHashMap 和 HashMap 是比较像的,放弃了原先分段锁的设计,转而对每一个数组格子加 synchronized 锁。我发现道格李写代码很喜欢写循环,循环进入的每一轮,状态是不同的,进而进到不同的分支中。我们具体看一下 HashMap 和 ConcurrentHashMap 的实现:
- HashMap 加 entry 时,顺序执行一堆 if-else 的判断,先判断数组是否已被创建,然后判断是否发生哈希碰撞,如果哈希碰撞再判断是否是红黑树节点……
- ConcurrentHashMap 加 entry 时,在一个无限循环当中,首次进来创建数组,再次进来判断是否是空链表,如果是空链表就直接 CAS 加入,如果加入失败了没关系,退出去,循环再进来的时候,进入到不是空链表的分支里,用 synchronized 阻塞尾插链表……
在实现 AQS 队列的时候,我就觉得道格李用循环用得是炉火纯青了……一方面体现在每次进入循环,执行的代码都不一样,另一方面体现在循环内部的各个 if 条件是有关联的(往回看代码就能看出来,第二个 if 条件获得了数组下标,结果用到了第四个 if 条件中)。
ConcurrentHashMap 同样采用
数组+链表+红黑树的设计,但是红黑树稍有区别,HashMap 的转红黑树条件是链表长度超过 8,ConcurrentHashMap 的转红黑树条件,在链表长度超过 8 的基础上,还需要数组长度超过 64。我猜测这跟 synchronized 锁有关,如果数组长度太小了,加锁会比较容易阻塞。ConcurrentHashMap 数组扩容跟 HashMap 一样,都是两倍,具体实现很复杂,支持多线程一起帮助扩容。在 putVal() 方法中就有判断 hash 值是否是 -1,如果是 -1 就代表着去帮助扩容数组。
JDK7 和 JDK8 的 ConcurrentHashMap 的 get() 方法都没有做并发处理,逻辑比较简单,主要依靠 volatile 关键字和 UNSAFE 包来确保并发安全。