正则表达式
十二月的第四周,来学习正则表达式。
工作时经常需要用到正则表达式来校验字符串,每次遇到都怵怵的,这周来扫除一下盲区。
正则表达式(regular expression),根据英文也可简写为 regex。“正则”这个中文翻译颇有民国风度,所谓公正而乎法则,今已查不到何处还在用此词,似乎只有编程领域在用。
正则表达式只用于字符串,用来检查字符串是否符合某种规定(例如只有字母、又例如没有数字等),或者是取出符合规定的字符串子串(用于后续替换等)。
例如下图,为匹配以 Hello 开头的字符串的正则表达式,成功匹配到了两条。
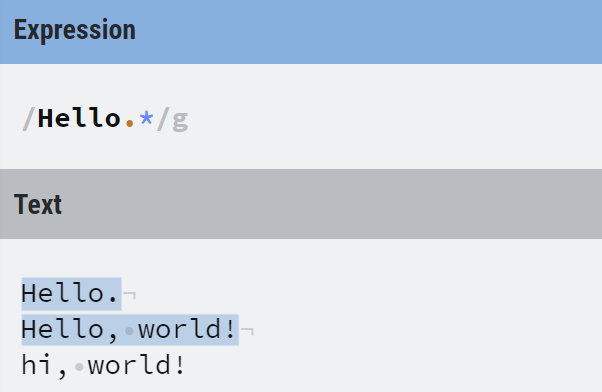
(上图截图自 https://regexr.com/ 网站,是一个很好用的正则表达式在线测试网站)
此外再安利一组入门正则表达式的视频:《表严肃讲正则表达式》,供入门使用。这组视频讲得很用心,不像大部分编程公开课跟倒泔水一样地倾泻几十个小时垃圾,我能感受到它是精心准备过的,很是喜欢。
正则表达式的概念不难理解,若不清晰用过一两次便懂。使用正则表达式若有困难,都是因为语法繁多,需要记忆的内容量大。下面整理了三张正则表达式的常用语法字符表,主要来源为菜鸟教程的正则表达式教程。分三张表,分别是:
- 非打印字符:转义后的字符,代表某一类字符
- 特殊字符:含特殊含义的字符
- 限定字符:字符次数限制
非打印字符
| 字符 | 描述 | 正确示例 | 错误示例 |
|---|---|---|---|
| \w | 数字、字母、下划线 | 1/a/A/_ | ./&/の/【/︹(空格)/ㄱ(换行) |
| \W | 除数字、字母、下划线以外 | ./&/の/【/︹(空格)/ㄱ(换行) | 1/a/A/_ |
| \s | 空白字符 | ︹(空格)/→|(制表符)/ㄱ(换行)/☇(换页) | 1/a/A/_/./&/♂ |
| \S | 除空白字符以外 | 1/a/A/_/./&/♂/张 | ︹(空格)/→|(制表符)/ㄱ(换行)/☇(换页) |
| \d | 数字(单个) | 1/2/3/4/5/6/7/8/9/0 | a/?/&/1234(整体) |
| \D | 除数字以外 | a/B/,/%/张/︹(空格) | 1/2/3/1234(整体) |
| \n | 换行符 | ㄱ(换行) | 1/a/A/_/? |
| \t | 制表符 | →|(制表符) | 1/a/A/_/? |
特殊字符
| 特殊字符 | 描述 | 正确示例 | 错误示例 |
|---|---|---|---|
| . | 除换行以外任意字符 | 1/a/A/%/_ | ㄱ(换行)/123(整体) |
| ^ | 从字符串开始的位置处匹配 | ^12 -> 12/123/12a | ^12 -×-> a12/abc12/ |
| $ | 从字符串结束的位置处匹配(倒着) | 12$ -> 12/abc12/012 | 12$ -×-> 123/12aaa |
| | | 或 | [1|2|3] -> 1/2/3 | [1|2|3] -×-> a/4/& |
| [] | 方框运算符,字符集合/范围/反向 | ||
| () | |||
| {} |
限定字符
| 限定字符 | 描述 | 正确示例 | 错误示例 |
|---|---|---|---|
| * | 匹配零个、一个或多个字符 | 12*3 -> 13/123/1223 | 12*3 -×-> 1 |
| + | 匹配一个或多个字符 | 12+3 -> 123/12223 | 12+3 -×-> 13 |
| ? | 匹配零个或一个字符 | 12?3 -> 13/123 | 12?3 -×-> 12223 |
| {n} | 字符限定n次 | 2{4} -> 2222 | 2{4} -×-> 222/22222(整体) |
| {n,} | 字符限定最少n次 | 2{2,} -> 22/222/22222 | 2{2,} -×-> 2 |
| {n,m} | 字符限定n-m次 | 2{2,3} -> 22/222 | 2{2,3} -×-> 2/2222(整体) |
除以上常用的语法字符之外,还有以下规则,需要单独注意:
[ ]
方括号表示字符集合,可配合 ^ 符合表示反向的字符集合,常见用法有:
| 示例 | 说明 |
|---|---|
| [12a] | 可匹配 ‘1’ 或 ‘2’ 或 ‘a’ |
| [1|2|a|,] | 可匹配 ‘1’ 或 ‘2’ 或 ‘a’ 或 ‘,’ |
| [1-9] | 可匹配 ‘1’ 或 ‘2’ 或 …… 或 ‘9’ |
| [a-z] | 可匹配 ‘a’ 或 ‘b’ 或 …… 或 ‘z’ |
| [^12a] | 可匹配除了 ‘1’ 或 ‘2’ 或 ‘a’ 以外的字符 |
| [^1-9] | 可匹配除了 ‘1’ 或 ‘2’ 或 …… 或 ‘9’ 以外的字符 |
()
圆括号代表同时匹配多个字符,如匹配 hello 这五个字符,可以使用 (hello) 来匹配。
但是除此之外,() 匹配到的字符串还会被缓存起来,缓存起来的子表达式可以在之后使用。
例如使用([nN]o)匹配 No, get out!,不光能匹配到 No,还能通过 $1oooooooo 将原文替换成 Nooooooooo, get out!。
| 示例 | 说明 |
|---|---|
| (hello) | 可以匹配 “hello”,并缓存起来 |
| (?:hello) | 可以匹配 “hello”,但不缓存结果 (用于匹配多字符但并不需要结果,有时能让正则表达式更简洁) |
| hello(?=AA) | 可以匹配 “helloAA……” 中的 “hello”,但是不能匹配 “helloBB……” 中的 “hello”,且不缓存结果 |
| hello(?!AA) | 不能匹配 “helloAA……” 中的 “hello”,但是可以匹配 “helloBB……” 中的 “hello”,且不缓存结果 |
| (?<=AA)hello | 可以匹配 “AAhello……” 中的 “hello”,但是不能匹配 “BBhello……” 中的 “hello”,且不缓存结果 |
| (?<!AA)hello | 不能匹配 “AAhello……” 中的 “hello”,但是可以匹配 “BBhello……” 中的 “hello”,且不缓存结果 |
贪婪
贪婪是编程和算法中常见的概念,意思是越多越好。
* 和 + 这两个限定符都是贪婪的,如果用 hello* 或者 hello+ 来匹配 hellooooooo,它们的匹配结果都是 hellooooooo,而不是 hell、 hello 或 hellooo 或是其他的。
在 * 和 + 后面加上 ? 就可以使匹配结果是非贪婪的(最小匹配)。按照上面的例子,hello*? 匹配的结果是 hell,hello+? 匹配的结果是 hello。
写几个看到过的正则表达式,举几个例子
身份证校验(简易版)
^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$不能包含数字
^[^\d]+$浮点数
^(-?\d+)(\.\d+)?$域名
^[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+$数字(包含负数、小数)
^-?[0-9]+(\.[0-9]+)?$
学习过正则表达式的基本语法之后,感觉在工作中还是不够用,还要学习 Java 中正则表达式的使用。
正则表达式从 JDK 1.4 之后出现,涉及到两个新类:Pattern 和 Matcher。Pattern 类代表一个正则表达式,而 Matcher 类代表一个正则表达式对一个字符串进行校验后的结果,例如:
1 | // 正则表达式,规则:不能包含数字 |
Pattern 类没有(对外的)构造方法,因此生成一个 pattern 对象只能通过 Pattern 类的静态方法。
如果只是想检验字符串是否符合要求(即只需要一个boolean值),那么使用 Pattern 类的静态方法就可以,pattern 对象是为了更多操作。
1 | String regex = "^[^\\d]+$"; |
Pattern 类多实现一些,用代码实现正则表达式的功能,而不是完全只用字符串来实现。例如它能指定正则表达式可以同时匹配大小写字母(指定后,正则表达式字符串即使只有 ‘a’,匹配时也可以同时匹配 ‘a’ 和 ‘A’),又或者可以用指定正则表达式分隔字符串,例如将一串带有数字的字符串,以数字为分隔拆分成多个子字符串。
Matcher 类多实现一些对匹配结果的处理,这一部分具体没怎么看,需要时再补吧。
最后提一句,Java 中使用正则表达式时,基本上要出现 \ 的地方,都要转义成 \\,例如 \d -> \\d。
本周就学习到这里了。
2020-03-08 补
发现平常在 Java 中使用 Pattern 类和 Matcher 类还是很频繁的,之前学习得不细致,得回来补一下。
Pattern
Pattern 类可以理解成是正则表达式,可以使用 Pattern 对象来对字符串进行正则校验。
不能通过 new 来创建 Pattern 对象,只能通过 Pattern 类的静态方法创建。
1 | Pattern pattern = Pattern.compile("\\w"); // 正则表达式:单个数字、字母或下划线 |
日常使用 Pattern 类有两个用途:
直接校验字符串,返回 true/false
1
2
3// 校验是否是qq邮箱
String regex = "^\\w*@qq.com$";
boolean matches = Pattern.matches(regex, "hellopz@qq.com");这里有一处暗坑,校验成功要求
全部匹配,如果是部分匹配,那么返回值将是 false。1
2boolean matches1 = Pattern.matches("[0-9]", "123"); // false
boolean matches2 = Pattern.matches("[0-9]*", "123"); // true生成一个校验过的结果,返回 Matcher 对象
1
2
3
4
5
6// 正则表达式:是否是数字
String regex = "[0-9]*";
Pattern pattern = Pattern.compile(regex);
// 生成对"123"校验的结果(结果是一个Matcher对象)
Matcher matcher = pattern.matcher("123");Matcher 对象能做更多的事情,比如部分校验、取出校验结果等。
Pattern 类的其他使用,例如指定正则模式 flag、分割字符串的 split() 方法(我好像觉得跟 String 对象的 split() 方法 没有任何区别?),感觉都不实用,不写了。
Matcher
Matcher 类可以理解成经过校验的字符串的校验结果,可以通过该对象处理校验结果。
Matcher 对象由 Pattern 对象的 matcher() 方法获取:
1 | // pattern表示正则表达式,方法内传入待校验的字符串 |
日常使用 Matcher 类也是两个用途:
检查字符串中是否含正则校验内容
1
2
3// 校验是否包含数字
Matcher matcher1 = Pattern.compile("[0-9]").matcher("12345");
boolean contains = matcher.find(); // true请注意理解 find() 方法的语义,find 的意思是找到了,并不代表完全匹配,换言之只需要字符串中有正则内容就可以。因此使用 matcher.find() 和 Pattern.matches() 是不等价的。
取出正则校验结果
这里有一个需要先指出的暗坑:在取结果之前,必须先执行 Matcher 对象的 find() 方法,如果不执行,将抛出
IllegalStateException异常:No match found(没找到匹配结果)。1
2
3
4
5
6
7
8// 正则表达式:数字(字母)数字(字母)数字(字母)
Matcher matcher = Pattern.compile("\\d+([a-z])\\d+([a-z])\\d+([a-z])").matcher("111a111b111c");
boolean find = matcher.find(); // true
String result = matcher.group(); // 111a111b111c
String result0 = matcher.group(0); // 111a111b111c
String result1 = matcher.group(1); // a
String result2 = matcher.group(2); // b
String result3 = matcher.group(3); // c使用 group() 方法可以捕获到正则结果,如果正则表达式中有
( )括起来的内容,这部分内容可以取出来。有两种常用的 group() 方法,一种是传入 int 值的 group(int group) 方法,另一种是无参的 group() 方法。
带 int 参数的 group() 方法,参数为 0 时代表整个表达式,为 1 时代表匹配到的第 1 个
( )内容,为 2 时代表匹配到的第 2 个( )内容……以此类推,正如上面的代码示例。如果参数是 n,但是实际上并没有 n 个匹配内容,会抛出
IndexOutOfBoundsException异常。无参的 group() 方法实际上就是 group(0),代表整个表达式。
此外还可以通过 groupCount() 方法获取匹配到
( )的数量。1
2// ...延续上面的代码
int count = matcher.groupCount(); // 3
Java 的正则表达式写到这里应该就可以了,足够日常用了。
2021-12-08 补
今年下半年,技术栈转 Go 了。
新写了篇文章,总结了 Go 的 regexp 包:《Go 标准库学习:regexp》。