Spring Cloud 入门
十月的第二周,来学习 Spring Cloud 。
Spring Cloud 在我眼里是一套东拼西凑攒出来的框架,学这个框架学的都是一个个分散的零件。
一切讲 Spring Cloud 教程的视频、书籍、博客,都是从微服务讲起的。讲技术之前先讲思想,来暗示技术的存在合理性。
微服务是个软件架构概念,一个大项目应该拆成多个小项目,各个小项目独立部署,松散耦合,各自实现小业务功能。微服务的对立面是单体式应用程序,一个应用程序内包含了所有需要的业务功能。
我理解的 Spring Cloud,是一个管理微服务的工具集。工具集,工具之集合也,意即 Spring Cloud 不是一个东西,而是一堆东西,它就是一个个分散的工具合在一起的总称。就像是下图展示的这样,Spring Cloud 是由 Eureka、Ribbon、Feign 等一个个零碎的组件组成的,学习 Spring Cloud 也应该是一个个逐个学习的。
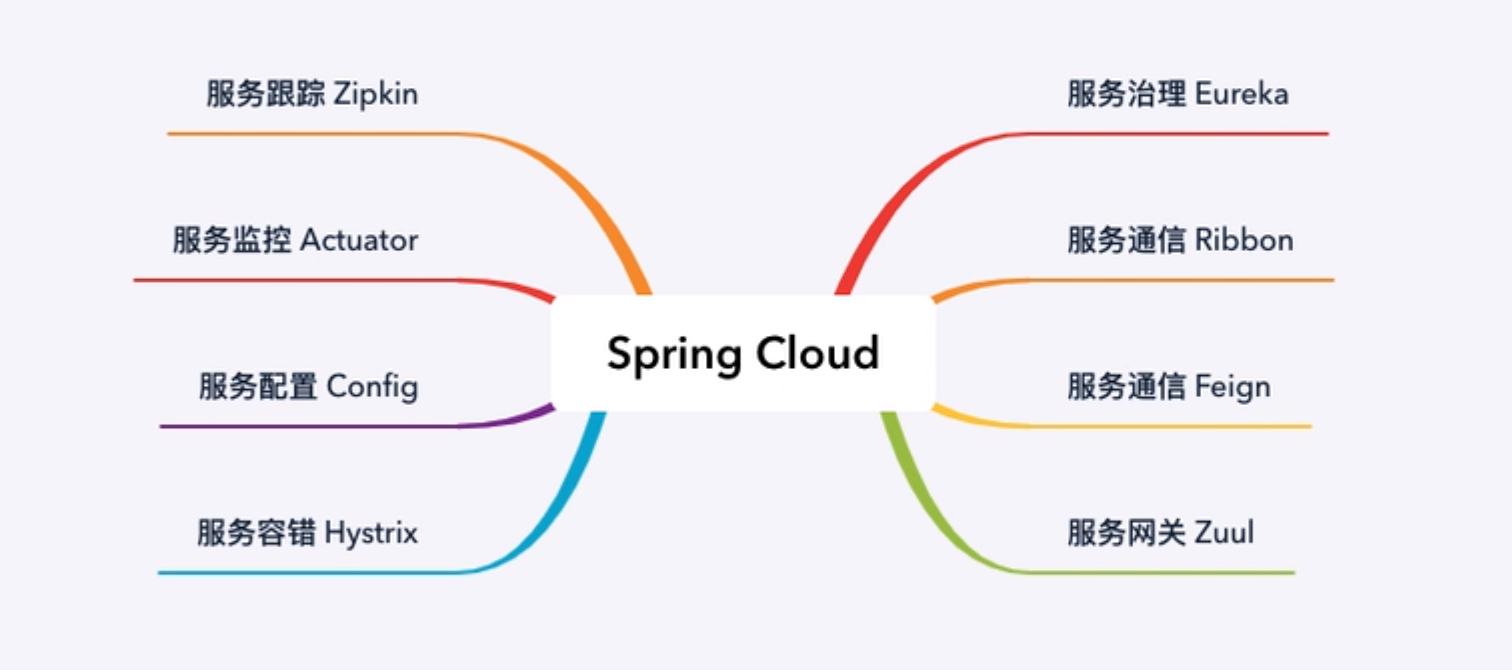
(这张图是我在 B 站的一个教学视频《Spring Cloud 从入门到实战》中,讲者所认为的 Spring Cloud 框架。BTW:我认为这个教学视频讲得很出色。)
Spring Cloud 这么多组件,大部分都是 netflix 提供的开源组件,导包的时候就能发现,artifactId 总是 spring-cloud-netflix- ……。我初看到 netflix 还有点惊讶,毕竟这是网飞的英文原名,但我还是以为这是重名巧合,后来反复去查才发现,这真的就是那家做在线视频的网飞公司。
总有知名品牌搞跨界来颠覆我的认知,网飞搞微服务架构技术给我的感觉,就像是卖轮胎的米其林给人推荐餐厅一样,怎么就没听说爱奇艺去做开源编程组件的……
我自知 Spring Cloud 是一套框架的内容,其包含的一个个组件是有整合过的,不是真的分散毫无关联的,但我依旧认为,在学习时把 Spring Cloud 理解成一个个分散的组件,是能更高效理解的方式。下文的内容,也是一个个分开来写的。
我认为微服务是一种很容易理解的架构,大项目分而治之。但是 Spring Cloud 的组件实在是有点多,为了方便理解,我还是举一个现实情景好了。
我觉得微服务就是个智能家居系统,如果有一个家用电器,能够同时看电视、洗衣服、吹空调、冰鲜食物等等(单体式应用程序),还是一件比较恐怖的事情,我们比较希望的事情是,电视是电视、洗衣机是洗衣机、空调是空调……每个家用电器做自己的事情(微服务)。
- 为了实现智能家居的效果,我们买了一个智能音箱(Zuul),对智能音箱喊,智能音箱帮我们去做事情。
- 当然,这个的前提是,家电和智能音箱连在同一个局域网里,智能音箱能找到家电(Eureka)。
- 我们的家电之间还要能互动(Feign),比如红外线感应器感应到我回家了,空调就自动打开。
- 当我们有多个相同的家电时,要合理分配(Ribbon),比如有两个扫地机器人,要让两个分开扫屋子。
- 当家电出故障时,要及时做出调整(Hystrix),比如空调坏了,智能音箱就不要一直让空调调温度了。
- 此外还要配置家电使用时段等信息(Config),监控家电(Actuator),查询家电是为何而工作(Zipkin)等等。
你能感受出来,Spring Cloud 就是一套协调微服务正常运行的框架。
学习 Spring Cloud 至少要有一点点的 Spring Boot 的基础,因为 Spring Cloud 这个框架是基于 Spring Boot 的,里面每个组件的配置过程,其实都是 Spring Boot 的内容,所以我们要先了解一下,Spring Boot 是怎么使用的。
Spring Boot,boot 这个词用得真是传神,你去查 boot 的意思,它有一个动词词性的释义:(计算机)启动、操作系统已安装。什么意思呢,就是说 Spring Boot 是一个帮你配好 Spring 几乎所有配置的框架,你使用它,相当于直接配好了所有东西,拿来就直接用。
对 Spring 没有任何了解,上来就看 Spring Boot 的人,可能并不理解程序员为何如此吹捧它,好像它实现的功能也就那么一回事。有这种感觉,是因为不清楚 Spring 的配置过程有多么繁琐,基本可以用“配置地狱”来形容。Spring Boot 的出现,是为了解决 Spring 配置过于复杂的痛点。写代码时你引了个包,加了个注解,实现了一个功能,看上去平平无奇,这个平平无奇就是 Spring Boot 的作用。
我们今天学习的是 Spring Cloud,由于它基于 Spring Boot,因此在配置方面,我们其实是在学习 Spring Boot 。
Spring Boot 使用起来可以简单地分两步走:
- 添加第三方依赖。
- 注解声明,我要使用 Spring Boot 啦。
第一步:添加第三方依赖。我采用 maven 来管理第三方依赖,maven 是一个管理项目的工具,对此我也基本处于小白状态,只是知道它可以用 xml 文件的形式来配置,以及简单地写写。
添加第三方依赖对于 maven 来讲是件很容易的事情,在 dependencies 中添加上需要的依赖就可以了。例如我要使用 Spring Cloud 其中一个组件 Eureka,我只需要在 Eureka 服务端的 pom.xml 文件中,添加这么一点代码。
1 | <dependency> |
第二步:注解声明要使用 Spring Boot。这一步在启动类中添加,启动类怎么说呢,可以认为是新建完工程模块之后,唯一的那个 java 文件里面的类,哎呀我也道行不够,反正就这么写:
1 |
|
上面这种是一种通用写法,是在声明这个类是一个 Spring Boot 的启动类。如果更具体一些,例如我要使用 Spring Cloud 中的 Eureka 组件,要声明某个类是服务端,就要多加个注解。
1 |
|
至于 @SpringBootApplication 等这些注解是怎么工作的,main 方法里面的 SpringApplication.run() 方法在干什么,这个就要自己去看 Spring Boot 的内容了。
Spring Boot 在设计之初就有一种理念,即“约定大于配置”,意思是说,我们约定好了就用某种方式来配置。比如说原来一个程序,里面有 A、B、C 三个地方要配置,A 有 5 种配置方法,B 有 3 种,C 有 4 种,这一排列组合就有 60 种配置方式,但是你得 A、B、C 一个个地手动配,大家都配烦了,这时 Spring Boot 配好了其中一种,说既然这种使用得最多,也就别一个个地配了,就用这种吧。Spring Boot 的代码,在字里行间中就有这种约定俗成的“潜规则”感,例如启动类起名都叫 xxxApplication.java ,别问,问就是约定俗成。但是潜规则这种东西,说不清道不明的,还是得自己多试试脾气。
Eureka
Eureka 是 Spring Cloud 的头号组件,它的使用方法也代表了 Spring Cloud 中组件的一般使用方法,所以我们借着 Eureka 来学习,Spring Cloud 一般是如何配置和使用的。但是在此之前,我们先要知道 Eureka 是做什么的。
Spring Cloud 是一种微服务架构,比如说原来一个项目实现 15 个功能点,现在这 15 个功能点拆分成 10 个小项目,由这 10 个小项目组合起来作为一个微服务大项目。如果用图示可能会更直观一些:
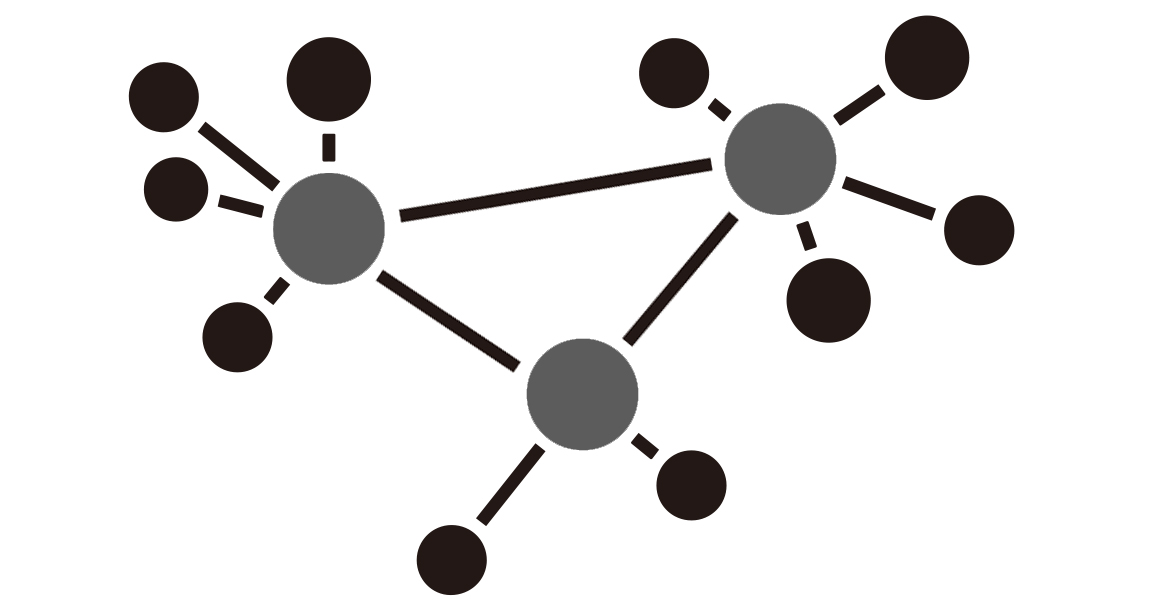
这是我认为的微服务架构示意图,像是局域网一样采用星型拓扑结构,每一个小黑点代表一个微服务,联结起来组成一个微服务群。
Eureka 正如上图中的黑线,它的作用是把一个个分散的微服务联结起来,让这些微服务组成一个集群,让每个微服务都能“登记在册”。
Eureka(音标 [juˈriːkə] ),用更为专业的术语来描述它,应该称它为“服务的注册和发现中心”,服务就是微服务,注册就是让一个个的微服务登记在册,发现就是在登记册中找到这一个个服务。
再换句话说,每个微服务,都要到 Eureka 那里签到(注册),要找服务的话,也要去 Eureka 那里去找(发现),也就是说,Eureka 是微服务的中介中心。
说来 Eureka 这个词还有点美式幽默,它是阿基米德发现浮力定律后兴奋地在大街上裸奔,边跑边喊“知道了!我知道了!”的那个词,当时的含义是“我终于找到浮力定律了!”。在微服务框架中,Eureka 的含义是“啊我发现这个服务了”,即代表某个服务在中心注册过了,也代表在中心找到了这个服务,颇有幽默意味。
Eureka 组件中有两种角色:服务端、客户端。如果用上张图来解释这两种角色,那么服务端是灰点,客户端是黑点,黑点(客户端)注册到灰点(服务端)之后,每次可以通过灰点找到黑点。其实呢这是一个 C/S 架构,Eureka 就是一个基于 C/S 架构而设计出来的组件。
现在我们来思考一下,如何使用 Eureka。我们通过 Eureka,目标是实现【把一个个微服务登记在册,以备用时查找】,加以思索会发现,Eureka 的功能是【服务注册和服务发现】这样很通用的功能,对于不同的微服务、不同的项目,功能也是一样的。我们并不需要改变功能,而应该改变例如 IP 地址、端口号等等的配置信息。也就是说,【功能】和【配置】是分开的,对于【功能】,所有的微服务都是一样的,既然都是一样的那就让框架去写,我们只写【配置】。
Spring Cloud 的组件使用起来基本都是这样子,你并不需要写代码,只需要写一写配置文件就可以了。
我们来看看,Eureka 的配置文件怎么写吧。
Spring Cloud 所有组件的配置文件,都可以在 resource 目录下创建一个 application.yml 的 yml 文件。刚才说了 Eureka 分为服务端和客户端,那么分开看:
Eureka 的服务端配置:
1 | server: |
Eureka 的客户端配置:
1 | server: |
照着配,用的时候再去理解。yml 文件是一种更人性化的配置文件格式,它采用 YAML 语言来编写,看一眼主要特征也就看出来了:靠缩进来表示层级。
差点忘了讲,代码中还是要写一行的,加一行注解,表示自己要使用 Eureka 组件。这行注解就加在上文提 Spring Boot 时,启动类的上方,写在 @SpringBootApplication 注解旁边:
1 | // 就是这行注解 |
如果是服务端,那么注解是 @EnableEurekaServer,如果是客户端,那么连注解都不用加。
我们其实相当于说完了 Eureka,只不过非常潦草,那回头来多看一看 Eureka 这个组件。Eureka 是 Spring Cloud 这一微服务框架的注册和发现中心,它专注的事情是一项历史悠久的内容:服务发现。我查询了相当长时间的资料,觉得目前的学习阶段,对于服务发现这一内容还是浅尝辄止为好:服务发现有两种模式,一种是【客户端发现模式】,一种是【服务端发现模式】,Eureka 属于前者。
关于 Eureka 的最基本原理,要知道的有这么几条:
- Eureka 采用 C/S 架构。
- Eureka 的客户端向服务端不停地发送心跳,来保持自己的注册状态,如果不发送了,服务端会移除它。
- Eureka 的服务端有自我保护机制,此时会认为网络本身有问题,不移除服务。
推荐下面三篇文章一读:
《作为服务注册中心,Eureka 比 Zookeeper 好在哪里》
Zuul
Zuul 是 Spring Cloud 的服务网关,能够实现动态路由、IP 过滤、数据监控等功能,并内部集成负载均衡功能,不过我们今天只看动态路由这一个功能。
了解 zuul 的作用,我们要先知道什么是网关(Gateway)。我理解的网关(这里的网关,可以更确切地叫做 API 网关)是一个入口,入口之外是用户,入口之内服务系统,用户并不需要知道系统内部是什么样子,用户只想完成功能,那么这时让网关去处理,用户走到网关面前,跟网关说我要做什么,网关就带用户过去。
这里说入口之外是用户,是一个场景化的说法,其实也不一定是用户,比如 A 服务想调用 B 服务,也可以通过网关来调用。维基对于网关的解释是“ 网关是转发其他服务器通信数据的服务器 ”,但我觉得也不是很易懂,可能网关这个概念就是难表述一些,但其实是一件很常见的功能。
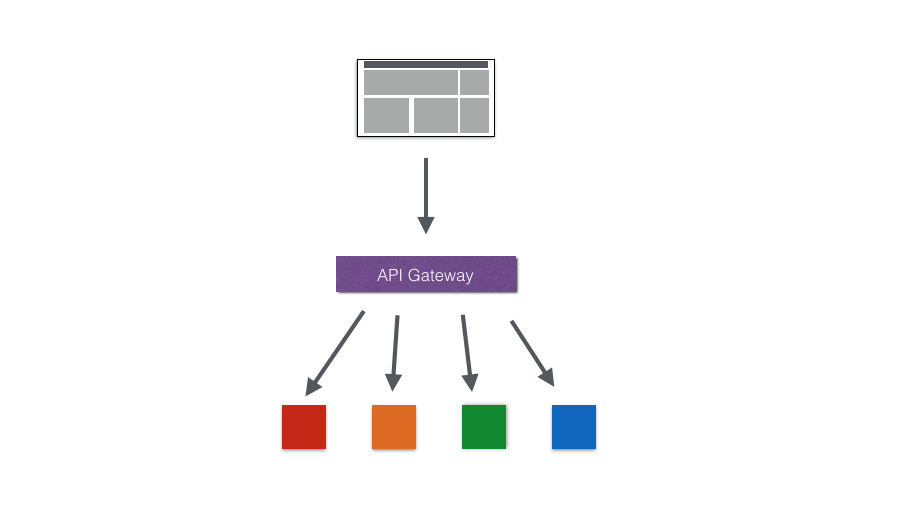
zuul 是 Spring Cloud 的 API 网关组件,实现服务网关的功能。
举一个很简单的例子:比如有一个服务叫 serviceA,这个服务的 url 地址是 http://localhost:8001/,还有一个服务叫 serviceB,它的 url 地址是 http://localhost:8002/,两个服务的 url 地址的区别在于端口号不同,如果调用的话是一件很糟糕的事情,因为既不便于识别,也不便于维护。这里只有两个服务,若是上百个,那真的是很折磨人。通过 zuul,可以通过新的 url 来访问服务,比如通过 http://localhost:8000/A 访问 serviceA,再通过 http://localhost:8000/B 访问 serviceB,这样就很直观,也很便捷。
你应该看出来了网关(尤其是 API 网关)的入口作用,它把控了内外的通道,使得【外部访问 -> 网关 -> 内部服务】。上述只写了网关可以实现动态路由的功能,其实既然把控了入口,也完全可以做 IP 过滤、数据监控等等的功能。但是我们今天只关注动态路由这个功能,也就是上面例子中的变更访问 url 地址。
我们来看一下 zuul 的配置文件,我写了一则示例放在下面:
1 | server: |
你定睛一看,发现这个配置文件一共配了四个块,前三个块都是 Spring Cloud 的通用配置内容:服务端口号、服务名、服务中心,只有第四个块,配置到了 zuul,而且只配置了一项内容。
配置的这项内容是,把服务名为 pz-eureka-client 的服务,路由到一个新的 url 地址上(** 代表任意 url):
1 | http://localhost:5752/client/** |
何其简单呐!
这一次启动类的注解是 @EnableZuulProxy,代码如下:
1 |
|
好吧,上面的配置文件简单,是因为 zuul 的那么多网关功能,只用到【路由】,其他功能都没有用 :P 。而且设置路由的时候,还使用了省略写法。我们首先把路由的不省略的写法写出来:
1 | # 省略写法 |
zuul 的配置还有一些别的可讲的:
1 | # 路由前缀 |
Ribbon
Ribbon 是 Spring Cloud 中负责负载均衡的组件。负载均衡,字面意思是指把负载合理地分摊出去,例如我们设计好了一个网站,后端有十台服务器,怎么能让十台服务器同时合理工作,而不出现有一台跑死、剩下九台闲死的状况,就是负载均衡的目标。维基对于负载均衡作用的阐释很得我心:
主要作用是将大量作业合理地分摊到多个操作单元上进行执行,用于解决互联网架构中的高并发和高可用的问题。
在微服务架构中,某个服务部署了多个是个常见的情况,那么当另一个服务需要调用这好几个同一服务时,该如何调用就是一个负载均衡的问题,Ribbon 的作用就是解决这个调用时的负载均衡问题。例如有 5 台服务器在同时运行 A 服务,B 服务该怎么调用 A 服务,是随机挑一个调用,还是找最闲的服务器调用,还是指定哪一台调用,这是个负载均衡的问题,需要 Ribbon 组件来处理。
下面该讲 Ribbon 的配置了,讲到现在是第三个组件,你应该发现,Spring Cloud 的配置通常是非常简单的。但 Ribbon 尤其过分,你甚至都可以不用配置 application.yml 文件,写一个注解就可以了。
1 |
|
注解的位置不再是启动类之上,而放在了 RestTemplate 类之上。RestTemplate 类是 Spring 框架发起 HTTP 请求的一个类,它在服务中采用 RESTful 风格(RESTful 风格自己去查)与 HTTP 服务进行通信,简化了操作,用后就会觉得非常优雅。
调用服务的时候,实际上也就是在发送 HTTP 请求,因此如果在调用服务时考虑负载均衡的问题,就要在发送 HTTP 请求的类—— RestTemplate 类上添加注解,加上 @LoadBalanced。
不用配置 yml 文件的原因是,ribbon 默认采用的负载均衡规则为轮询(轮流访问服务器),如果你想使用别的负载均衡规则,那还是要配置一下,例如:
1 | pz-eureka-client: # 要调用的服务的服务名(需要负载均衡的那个) |
下面是 ribbon 的负载均衡策略说明,来源:《ribbon负载均衡策略》
| 类 | 中文 | 描述 |
|---|---|---|
| RandomRule | 随机策略 | 随机选择server |
| RoundRobinRule | 轮询策略 | 按顺序循环选择server |
| RetryRule | 重试策略 | 在配置时间内选择server不成功,则一直尝试选择一个可用的server |
| BestAvailableRule | 最低并发策略 | 逐个考察server,如果server断路打开,则忽略,再选择并发连接最低的server |
| AvailabilityFilteringRule | 可用过滤策略 | 过滤掉一直连接失败并标记为circuit breaker tripped的server,过滤掉高并发连接的server |
| WeightedResponseTimeRule | 响应时间加权策略 | 根据server的响应时间分配权重,响应时间越长,权重越低,被选择的概率越低;响应时间越高,权重越高,被 选中的概率越高 |
| ZoneAvoidanceRule | 区域权衡策略 | 综合判断server所在区域的性能和server的可用性轮询选择server |
Hystrix
Hystxic 是 Spring Cloud 的容错框架,也被称为熔断器。在高并发访问下,系统服务的稳定性非常重要,各种不可控因素都会影响服务的运行,例如网络连接突然变慢、服务脱机、访问量激增等等,Hystrix 就是用来让微服务正常运行的一套容错组件。这一容错组件能实现很多功能,例如隔离、降级、熔断、监控等等。
Netflix 这家公司真的是起名鬼才,Eureka 的意思是阿基米德裸奔时喊的“我发现了”,Hystrix 的意思是豪猪(Hystrix 的 logo 也是一只豪猪),表示这个组件跟豪猪一样浑身是刺能很好地保护自己。我看博文的时候,看到有一哥们说:
netflix 使用这畜生来命名这框架实在是非常的贴切。
太草了。
Hystrix 最常用的三个功能分别是资源隔离、降级、熔断。
资源隔离
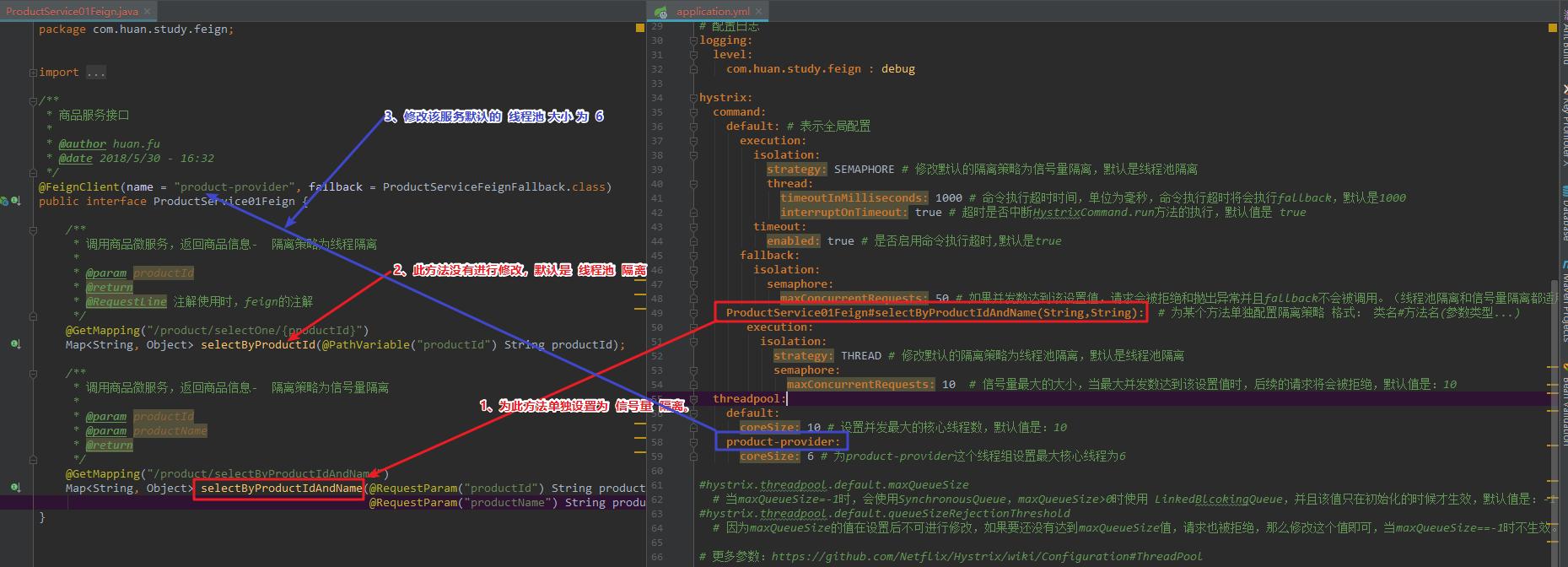
Hystrix 的隔离分为两部分,分别是线程池隔离和信号量隔离。
举个具体的例子,来解释这两种隔离方法。现在有两个服务:服务1和服务2,原本这两个服务一起运行,因为某些原因,服务1的访问量特别大,把服务器给挤崩了,结果服务2跟着遭殃,也无法使用了。线程池隔离是指,给服务1和服务2分别设置一个线程池,服务1的访问在自己的线程池当中,即使自己崩了也不会影响服务2。信号量隔离是指,服务1和服务2仍然共用一个线程池,但是给这个线程池设置一个最大访问量,超过了就不接受新的访问,保证服务器不崩。
线程池隔离有一定的性能损耗,但是依旧是默认的资源隔离策略,毕竟信号量隔离会直接丢弃请求。当服务类型很多,并发量又大,建立线程池损耗明显亏损较多时,建议采用信号量隔离。
这一块的配置,emm,我象征性地找了一张图,入门嘛,不学了哈哈哈。(图片来源找不到了,抱歉……)
降级
当服务负荷太高,已经无法继续下去的时候,为了不让请求阻塞,让服务器崩溃掉,可以事先准备好一个“次等”的返回结果,例如告知用户【抱歉服务器崩溃了】,或者只完成一部分核心服务,至少不会让请求无限地进行下去。这个事先准备好的“次等”的返回结果,就是降级(fallback)。
一般服务降级的触发原因有两种,一种是线程池满了,另一种是请求超时。
降级的使用方法,是在一个接口方法之上,增加
@HystrixCommand注解,标明当服务崩溃时,要跳转到哪个降级接口上。部分代码如下:1
2
3
4
5
6
7
8
9
10
11
12// 原接口方法
(defaultFallback = "fallClass")
("{id}")
public String queryById (@PathVariable("id") String id) {
String url = "http://userService/user/" + id;
return restTemplate.getForObject(url, String.class);
}
// 降级接口方法
public String fallClass (String id) {
return "服务器异常,无法查询用户";
}Hystrix 的配置参数与方法,在这里暂时不提。
熔断
我在三年前第一次听到“熔断”这个词,那时中国股市引入了熔断机制,如果当日股市的涨跌幅超过 5 %,熔断机制开启,股市暂停 15 分钟,暂停回来后涨跌幅超过 7 %,熔断机制再次开启,股市直接停盘。我听说股市里引入熔断的概念是为了设定一个阈值,超过阈值就暂停,让股市冷静冷静。不过当时的中国股市不是很容易冷静,开盘十几分钟就熔断,一恢复又熔断,总共交易了不到 20 分钟当天就收市了,这事一发生,第二天熔断机制就被废除了。
Hystrix 的熔断机制指的是,当服务器的错误率达到某个设定值时,服务暂停,之后的所有请求全部丢弃,之后服务会去试探是否恢复正常、能否重启,试探成功就重启继续运行。
这里的错误率、熔断时间、重启要求等,都是要进行配置的地方。这里需要配置的有点多,Hystrix 也有一套默认配置值,我觉得就暂且不深探究了。
Feign
Feign 是 Spring Cloud 的服务间通信工具。这个基本上是 Spring Cloud 中最重要的组件,因为微服务作为一个集群,总是要相互调用共同协作的,Feign 的作用就是微服务之间的通信。不使用 Feign 也能通过 RestTemplate 类等方式进行通信,但是 Feign 是 Spring Cloud 已经封装好的,使用起来更为优雅快捷的组件,所以一定要学习。
Feign 算是 Spring Cloud 的集大成者,它集成了 Eureka、Ribbon、Hystrix 等组件(因此默认支持负载均衡和服务熔断),支持 Spring MVC 注解,在此之外还基于注解简化操作,因此你可以认为,Feign 是一个活儿全的服务通信工具。(活儿不全的服务通信组件是 Ribbon + RestTemplate)
在这里我们先说使用方法,再说配置。
服务A要调用服务B的接口方法,正常的操作是这样的:服务B有几个接口对外开放,可以调用,任何地方都可以在允许的情况下,通过发送 HTTP 请求来调用服务B的接口,服务A也不例外。因此服务A想调用服务B的接口,也要在得知服务B的请求 url 前提下, 向服务B发送 HTTP 请求(可以通过 RestTemplate 来发送)。
Feign 的作用在于,发 HTTP 请求这种事情大同小异,我提供一个模板,你照着这个模板把地址之类的参数写清楚,我帮你发 HTTP 请求。顺便我帮你把负载均衡、服务容错这些事情一起处理了。
例如下面的这段代码(涉及到一点 Spring MVC 的知识,将就着看一看):
1 | // 用 Feign 来实现一个接口,接口中调用了服务B的获取用户信息接口 |
1 | // 使用 Feign 所定义的接口,让服务A能够在不发送 HTTP 请求的情况下,调用服务B的获取用户信息接口 |
代码分上下两块。上面的代码是使用 Feign 组件,下面的代码是服务A调用服务B的接口。
原来呢,下面的代码,即服务A调用其他服务的接口,是需要自己发送 HTTP 请求的。现在注入了 Feign 之后(@Autowired 那块),直接调用 Feign 就可以了。为什么呢,因为在上面的代码中,Feign 已经连接上服务B了。
梳理一遍,照着代码从上到下具体走一通。
我们首先定义了一个接口类:
FeignProviderClient类,该类通过注解@FeignClient表明它要使用 Feign 组件,并且指明它要连接的服务是一个名为pz-service-B的服务(服务B)。在刚刚定义的接口类
FeignProviderClient类中,声明了一个方法getUser,这个方法的作用是通过用户ID获取用户信息。但是这个方法并没有实现类,它只是单纯地声明了出来:有这么一个方法。为什么呢,因为这个方法在服务B那里实现,在这里我们并不需要去实现它,我们只需要声明它的存在,当使用它时,让 Feign 去发送请求调用方法。
我们又定义了一个 Controller 类:
FeignHandler类,这个类是我们服务A的一个 Controller 类。在这个
FeignHandler类当中,我们首先自动注入了FeignProviderClient类。在这个
FeignHandler类当中,我们新定义了一个接口方法getUserFromServiceB,这个方法的目的是,调用服务B的接口,通过用户ID拿到用户信息。这个新的接口方法的具体实现,就是使用刚刚定义的 Feign 接口类里面的方法。我们调用 Feign 接口类里面声明的方法,怎么发请求,怎么拿到数据,这个让 Feign 去解决。
写一个使用的更全面一点的 Feign 接口类,注解属性的作用已备注:
1 | ( |
我们还是写一点原理,下面这段内容引自《使用 Spring Cloud Feign 作为 HTTP 客户端调用远程 HTTP 服务》。
@FeignClient用于通知 Feign 组件对该接口进行代理,使用者可直接通过@Autowired注入。Spring Cloud应用在启动时,Feign 会扫描标有@FeignClient注解的接口,生成代理,并注册到 Spring 容器中。生成代理时 Feign 会为每个接口方法创建一个 RequetTemplate 对象,该对象封装了 HTTP 请求需要的全部信息,请求参数名、请求方法等信息都是在这个过程中确定的,Feign 的模板化就体现在这里。
最后我们来补 Feign 的配置,其实跟前文的任何一个组件都差不多,启动类加注解,application.yml 文件里配置信息。
启动类:
1 |
|
application.yml 配置文件:
1 | feign: |