jpa 实体关联注解
九月的第二周,来看 Jpa 注解开发实体关联,Spring Cloud 下周再说。
被 Jpa 实体关联搞得有点烦,两个月了也没完全清晰,特来写一篇文章把常见关联情况都试一遍。
从 ORM 框架说起。
ORM( Object-Relational Mapping ),对象关系映射。我们平常操纵的数据库都是关系型数据库(关系:表与表之间存在关系,例如从【部门表】可以查到【员工表】)。 Java 是一门面向对象的语言,它希望与对象打交道,而不是与数据库、与表打交道,通过 ORM (对象关系映射) 实现对象之间建立起关系。
术语一些: ORM,把关系数据库的表结构映射到对象上。
我们首先厘清一下概念。
从大类上分,有两类:数据库、实体。
数据库:表 + 字段
1
2
3
4
5
6├── 部门表
│ ├── 部门ID (字段)
│ └── 部门名(字段)
└── 员工表
├── 员工ID (字段)
└── 员工名(字段)实体:类 + 属性
1
2
3
4
5
6├── 部门类
│ ├── 部门ID (属性)
│ └── 部门名(属性)
└── 员工类
├── 员工ID (属性)
└── 员工名(属性)
数据库中,表之间的关联,是通过外键做到的,具体内容我们不讨论,这个去看数据库和 SQL 相关。
实体中,类之间的关联,可以通过注解来实现,这是我们这篇要详细讨论的。
顺便一提命名规则。
数据库的命名规则,基本使用下划线命名法,例如:department_id(部门ID)。
实体的命名规则,基本使用驼峰命名法,例如:departmentId(部门ID)。
注解是 JDK 1.5 引入的内容,原理基于反射,使用起来非常方便,Spring 中大量使用,具体不细叙。
使用注解开发实体关联,有两种途径:
@OneToOne、@OneToMany、@ManyToOne、@ManyToMany这四个注解是一类。除了
@ManyToOne这个注解之外,其他三个注解都有mappedBy属性,用于关联实体。@JoinColumn注解,用于关联实体。(但是还是要加上@OneToOne等关联注解的,两个注解一起使用)
要注意的是,这两种注解关联的方法,不能一起使用,只能选择一种使用。
注解填写属性
这两种注解,填写的属性是不同的。
mappedBy :类层面,关联的全都是【实体类】中的【属性名】
1 | // departmentId :类中的属性名 |
@JoinColumn:字段层面,关联的全都是【表】中的【字段名】
1 | // department_id :表中的字段名 |
多说一句, @Table、 @Column、 @JoinTable、 @JoinColumn、@JoinColumns,这些都是一类的,填写的全都是数据库中的字段名(下划线命名法的那些)。
正式开始。
建两个实体类,Department 和 Employee ,各有 id 和 name 两个属性。
1 |
|
1 |
|
后续代码会略写。
@OneToOne 一对一映射
场景:一个部门里只有一个员工,同样的,一个员工只属于一个部门。
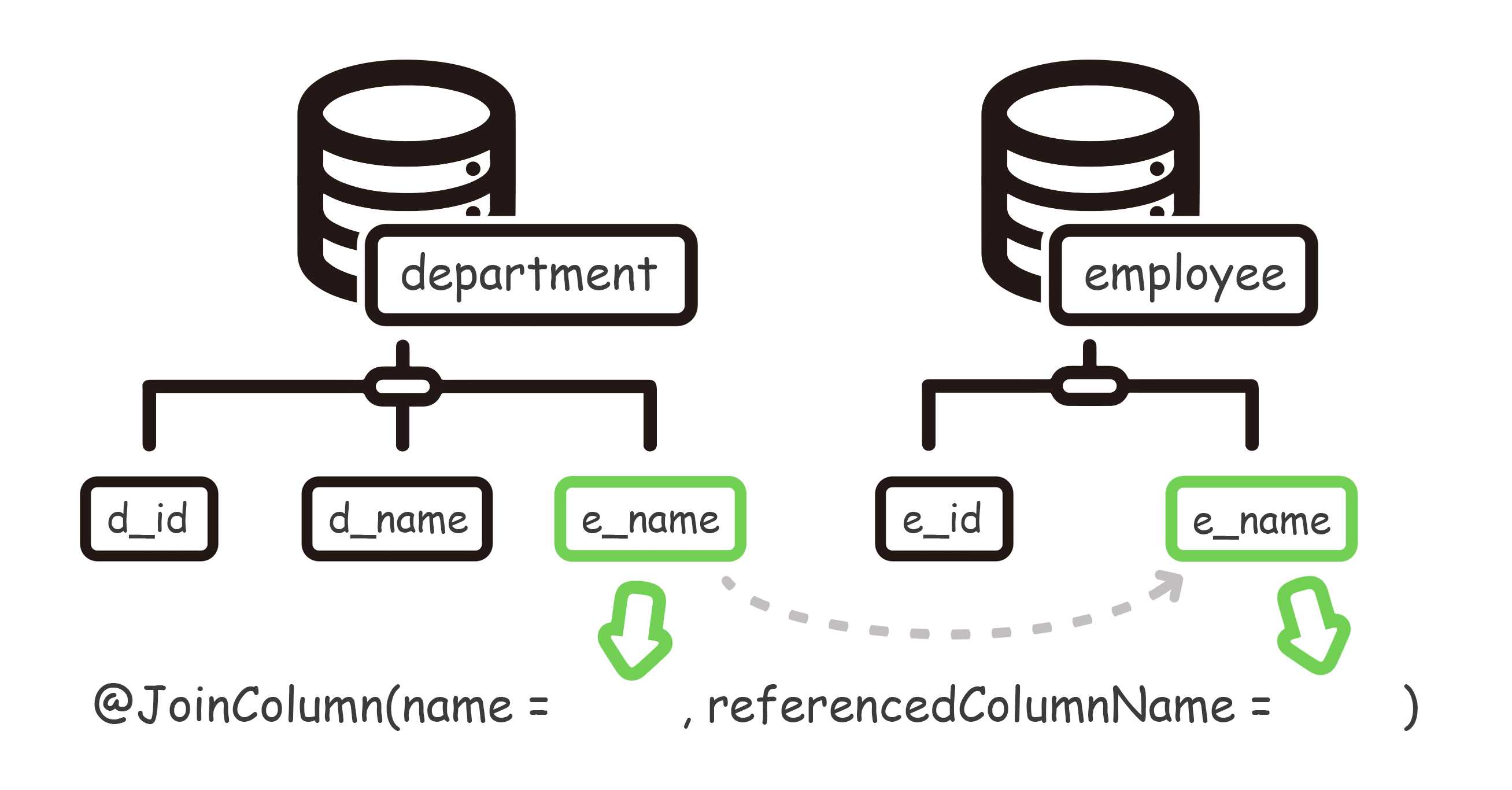
@JoinColumn
1 | public class Department implements Serializable { // 部门实体 |
注解中的属性:
name:【己方】实体的【数据库字段】referencedColumnName:【对方】实体的【数据库字段】(如果是主键,可以省略)
@OneToOne(mappedBy = “…”)
1 | public class Department implements Serializable { // 部门实体 |
1 | public class Employee implements Serializable { // 员工实体 |
对于 @OneToOne 注解,mappedBy 只有一种使用方法,那就是对方先关联自己,自己反关联回去。(因此无法通过 mappedBy 来实现一对一的单向关联,如若一对一关系使用 mappedBy ,必定是双向关联)
上面的代码实现了这样的功能:【部门类】首先关联了【员工类】(通过 @JoinColumn 注解),把员工作为自己的一个属性。【员工类】通过 mappedBy 反关联回去【部门类】,其中 mappedBy 所指向的值,就是部门类已经关联好的员工类属性。
换句话说,一对一的关联关系是由【部门类】所创建和维护的,mappedBy 自身不关联,它只是顺着这层已经存在的单层关联,顺藤摸瓜地反关联回去。
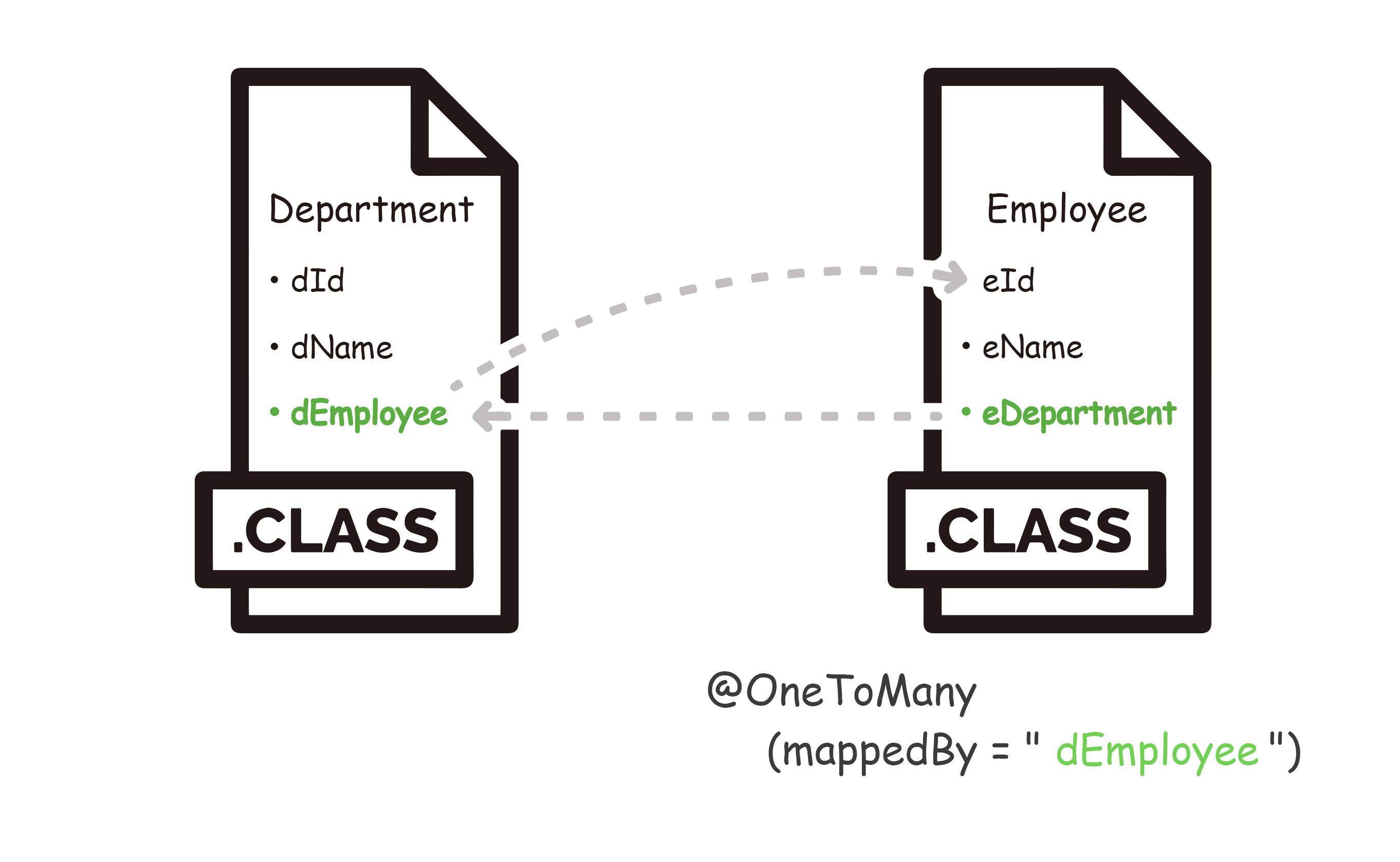
@OneToMany 一对多映射
场景:一个部门里有多个员工。
@JoinColumn
1 | public class Department implements Serializable { // 部门实体 |
注解中的属性:
name:【对方】实体的【数据库字段】referencedColumnName:【己方】实体的【数据库字段】(如果是主键,可以省略)
(发现了吗,刚好是跟一对一关系是反过来的)
这是个很有意思的事情,为什么这里反过来了呢?这个我们在后文的分析中再讨论。
@OneToMany(mappedBy = “…”)
一对多的情况下,mappedBy 有两种使用方式。
跟一对一关联一样,首先对面已经关联好自己,自己只需要反向关联回去即可,
mappedBy的值是自己在对方类中的属性名。(在这种情况下,必须双向关联)1
2
3
4
5public class Department implements Serializable {
// ...(省略)
(mappedBy = "employeeName") // 匹配自己在对方的实体属性
private List<Employee> ownEmployeeList;
}无需对方关联,直接去关联对方的外键属性。(在这种情况下,虽然使用了
mappedBy,但是依旧是单向关联)1
2
3
4
5public class Department implements Serializable {
// ...(省略)
(mappedBy = "departmentId") // 匹配对方的外键
private List<Employee> ownEmployeeList;
}但是这样单向关联有一个前提:对方的外键关联自己时,必须关联自己的主键。
比较简单,就不画图了。
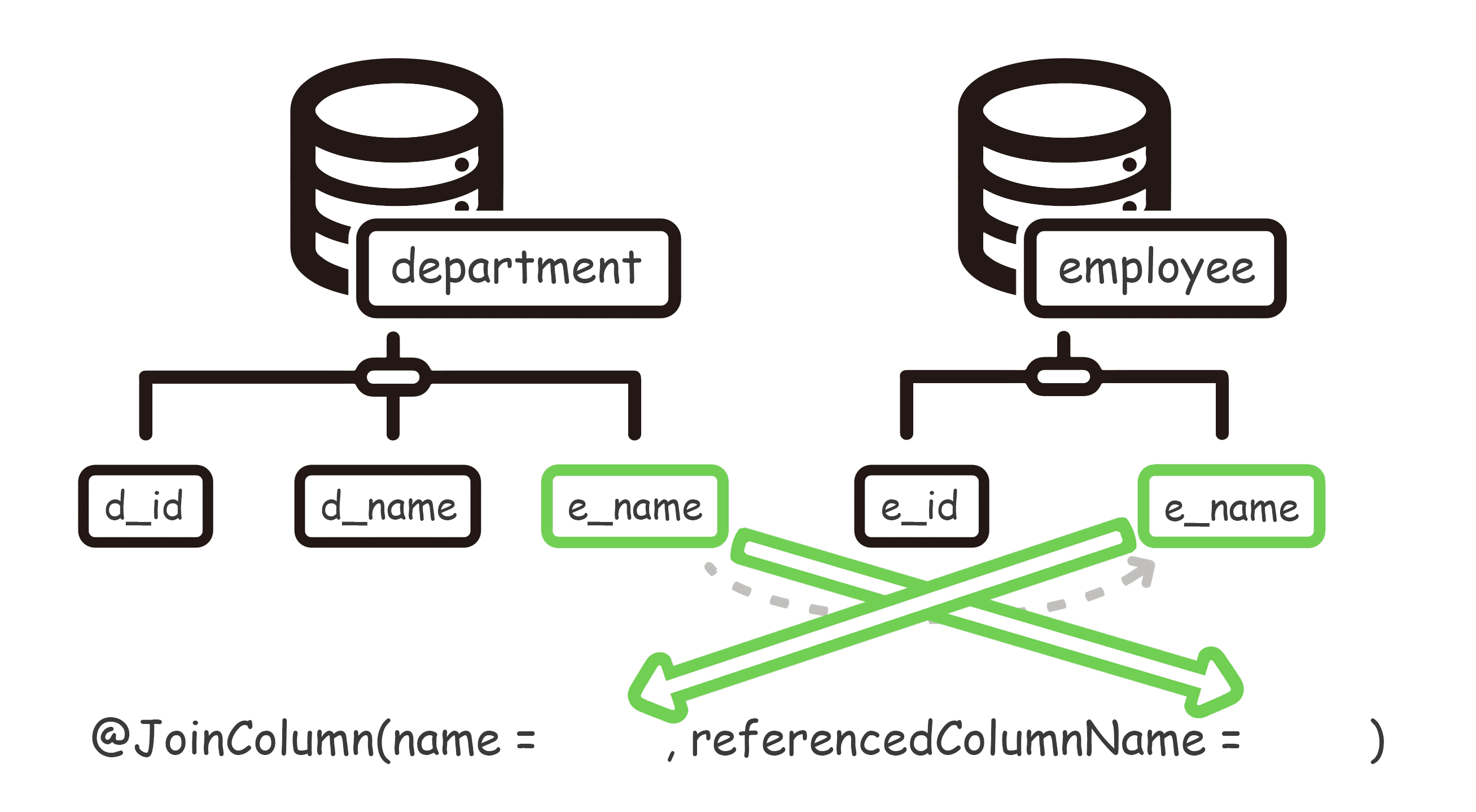
@ManyToOne 多对一映射
场景:多个员工归属于同一个部门。
@JoinColumn
1 | public class Employee implements Serializable { // 员工实体 |
注解中的属性:
name:【己方】实体的【数据库字段】referencedColumnName:【对方】实体的【数据库字段】(如果是主键,可以省略)
多对一关联( ManyToOne ),和一对一关联( OneToOne ),在使用 @JoinColumn 时,是一模一样的。
也就是说,一对一、多对一的关联,和一对多的关联,在 name 和 referencedColumnName 上,是刚好相反的,这个我们一会分析。
❌ mappedBy
@ManyToOne 不存在 mappedBy 属性。
因为 mappedBy 的原理是把关联的任务交给对面去做,员工有N个,部门只有1个,员工让部门去维护关联,一个部门是无法同时关联N个员工的,因此不存在 mappedBy 属性。
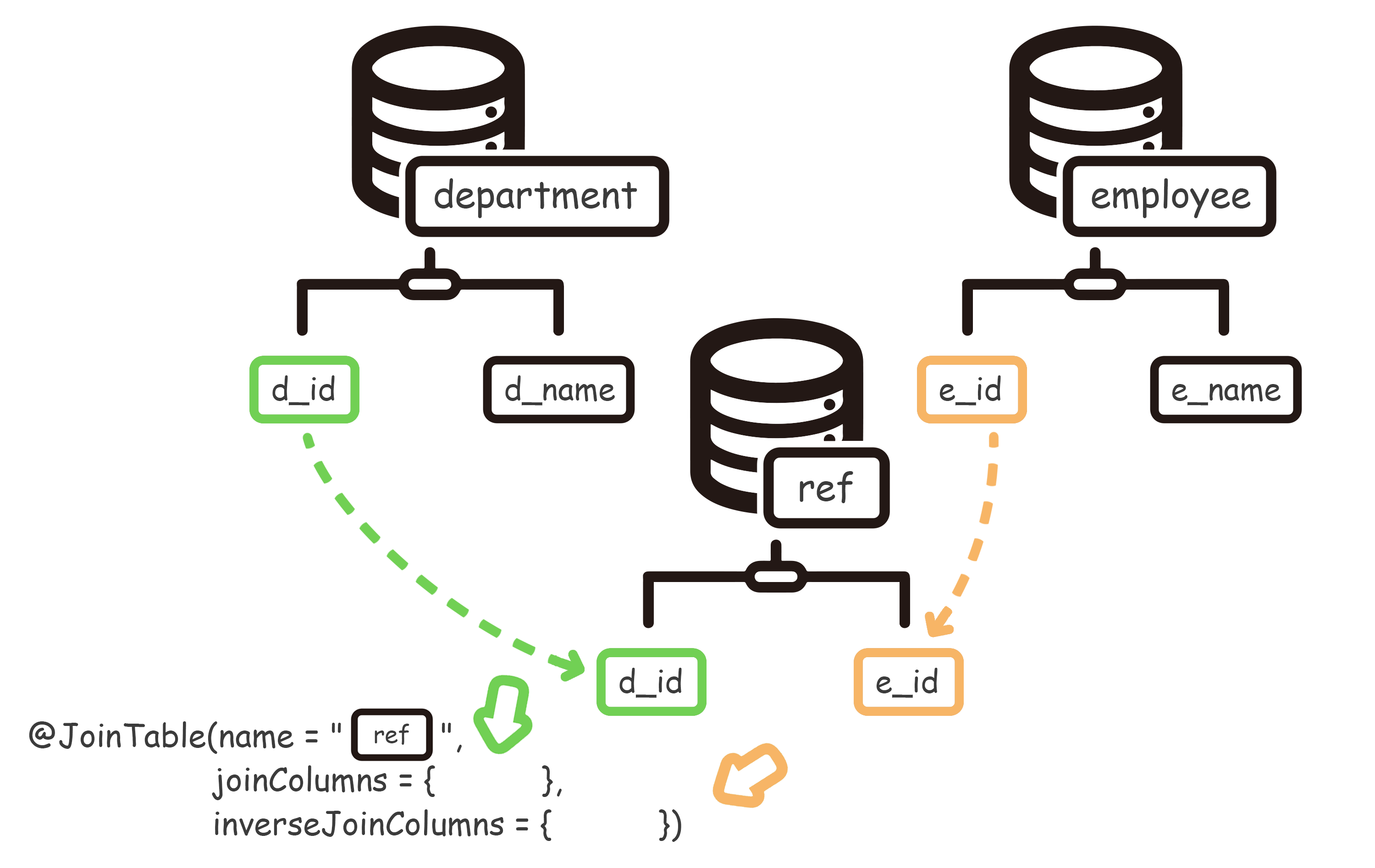
@ManyToMany 多对多映射
场景:一个部门内有多个员工,但是同时,一个员工也可以属于多个部门。
@JoinTable
1 | public class Department implements Serializable { // 部门实体 |
多对多关联,是需要自己建一张中间表的。粗略一想就会发现,多对多,双方都是多,无法实现一方用外键关联另一方,所以必须有中间表。(但是不需要为这张中间表创建实体类)
除了新增一张表之外,连注解也发生了改变。原先是 @JoinColumn ,join 到字段中,现在是 @JoinTable ,join 到表中。
注解中的属性:
name:【中间表】的【表名】joinColumns:【己方表】与【中间表】关联(按 @OneToMany 的方式来)inverseJoinColumns:【对方表】与【中间表】关联(按 @OneToMany 的方式来)
@ManyToMany(mappedBy = “…”)
1 | public class Employee implements Serializable { // 员工实体 |
只有一种使用方法,跟一对一关联( OneToOne )、一对多关联( OneToMany )都具有的使用方法一致:mappedBy 属性值是自己在对面实体类中的属性名,即必须双向映射。
四类关联:一对一、一对多、多对一、多对多,已经都走过一遍了。现在分析一下两种注解方式( @JoinTable 就懒得提了)。
@JoinColumn
我所理解的 @JoinColumn ,它的本质是 @Column ,从本质上来说,它并不是在做关联,它是在做映射,它把【数据库】和【实体】映射起来,使用这类注解能够实现:数据库中的一个字段,对应着,实体类中的一个字段。所以,它在做的事情,并不是把【部门】和【实体】关联起来,而是把【表】和【实体类】映射起来(但是与此同时,也就关联起来了两个实体)
1 |
|
刚才我们发现,【1 - 1】、【N - 1】的使用方法是相同的,但是【1 - N】刚好反了过来,这是为什么。
是因为,@JoinColumn 根本就不关心它所在的实体类是谁,它的 name 属性指向的,永远都是外键。因为外键始终在【多】的一方(一对一的话就默认自己是多),因此 name 属性值为【多的一方的外键】。
有关 @JoinColumn 自动建表的事情,我还没有弄清楚。
mappedBy = “…”
mappedBy 通常出现,都是为了做双向关联,而且对于 @OneToOne 和 @ManyToOne 而言,mappedBy 只能做双向关联。
我们在文章开头就指出,mappedBy 是针对【实体类】而做操作的,它的值是本类在对方类的属性名。我们再理一遍,它要等对方关联自己之后,自己顺着这层【已经建立起来的联系】,反关联回去。
这么做的道理是,A 关联 B,B 不应该再去建立新的关联关系,去重新关联 A(当然你硬要这么做也可以),而应该根据 A 关联 B 的这层关系,自动地找回去。这叫做:
本类放弃控制关联关系,关联由对方去控制。
很奇怪的一件事是,对于三种能使用 mappedBy 属性的注解: @OneToOne 、@OneToMany 、 @ManyToOne ,它们有一种统一的使用方法(即本类在对方类的属性名)。但是对于 @OneToMany ,它有第二种使用方法,它仿佛可以不需要对面先建立联系,直接使用 mappedBy 指向对方类的外键属性。
这样做的原理是,依旧让对方维护关联关系,但是必须由对方的【外键】关联己方的【主键】(如果使用 @JoinColumn 可以由对方的【外键】关联己方的【任意键】)。
也就是说,在一对多的关系中,【一方】想去关联【多方】,但是又不想自己去维护关联关系(因为一对多时,维护关联关系的话,代码会自动地创建出来一张新表),因此【一方】使用 mappedBy 让对面来处理关联关系。对面是怎么做关联的呢,是通过外键关联主键的方式关联的。
坑
最后说一说 Jpa 和注解关联的各种坑。
驼峰命名法和下划线命名法的自动转换
我还没查清具体的原因,是 Spring 框架还是 hibernate ,总之现在框架能自动把数据库中的【下划线命名法】映射到实体类中的【驼峰命名法】。
例如,正常来讲,实体类中的属性应该要通过
@Column配置映射关系。1
2
3
4
5
6
7
8
9(name = "pz_department")
public class Department implements Serializable {
// 这里通过 @Column 注解
// 将部门表中的【department_name】字段映射到部门类中的【departmentName】
(name = "department_name")
private String departmentName;
}但是实际上,就是不加
@Column注解,框架也能自动映射。1
2
3
4
5
6
7
8(name = "pz_department")
public class Department implements Serializable {
// 部门表中的【department_name】字段,自动映射到部门类中的【departmentName】
// 框架能够自动将下划线命名,转换为驼峰命名
private String departmentName;
}但是!一定不要这么做!
因为在做关联时,有可能会生成新表,如果之前没有加
@Column注解映射到数据库的话,新表的字段,将不会是原表中的字段名(下划线命名),而将是实体类中的属性名(驼峰命名),这时再去做关联,会报错。1
Caused by: org.hibernate.MappingException: Unable to find column with logical name: employee_name in org.hibernate.mapping.Table(pz_employee) and its related supertables and secondary tables
报错信息:【employee_name】字段,在【pz_employee】表以及其他相关表中找不到。
报错原因:因为在其他相关表(自动创建)中,字段名是【employeeName】。
进行双向关联时,循环打印
部门关联员工,员工关联回部门,部门再关联回员工……程序运行本身不会出现问题,但是如果打印出来,就会造成关联上的死循环,直至溢出。
想要解决的话,就在其中一个类的该属性上加上 JSON 相关的注解,让这个属性不进行序列化。
例如通过
fastjson中的@JSONField(serialize = false)注解。1
2(serialize = false)
private Department department;
@JoinColumn(name = "...")属性映射不能重复上文中分析过,
@JoinColumn注解本质上是对数据库和实体类进行映射。如果某一数据库中的字段,已经映射到某属性上了,在@JoinColumn中的name属性里再次映射,就会出现问题:到底映射的是哪一个呢?1
2
3
4
5
6(name = "belong_department_id")
private String belongDepartmentId;
(name = "belong_department_id", referencedColumnName = "department_id")
private Department belongDepartment;例如上面这段代码,就会报错:
1
Caused by: org.hibernate.MappingException: Repeated column in mapping for entity: com.app.ykym.modules.test.entityAndRepository.Employee column: belong_department_id (should be mapped with insert="false" update="false")
解决方法在报错信息里也说明了:重复映射的两个属性,选一个,让它
insert="false" update="false"(写在注解里),意思是让其中一个属性放弃更新和插入数据库的权限。(但是
@OneToMany时,@JoinColumn(name = "...")是可以重复的)