java IO
八月的第三周,来学习java IO系统。
IO是Input(输入)和Output(输出)的简称,合在一起就是输入输出。我们这里说的输入输出,都是相对于java程序而言的,我把硬盘中的文件读到java程序里,这是输入;我把java程序中的图片上传到博客里,这是输出。了解输入输出的第一件事,就是搞清楚入和出的方向是什么。
IO系统是一个超级庞大的系统,不论是方法(函数)还是设计模式,光从数量上就令人望而生畏。这周尽量多学,学到哪里算哪里吧。
任何有关java IO的学习,永远是从5个基础的类开始的。
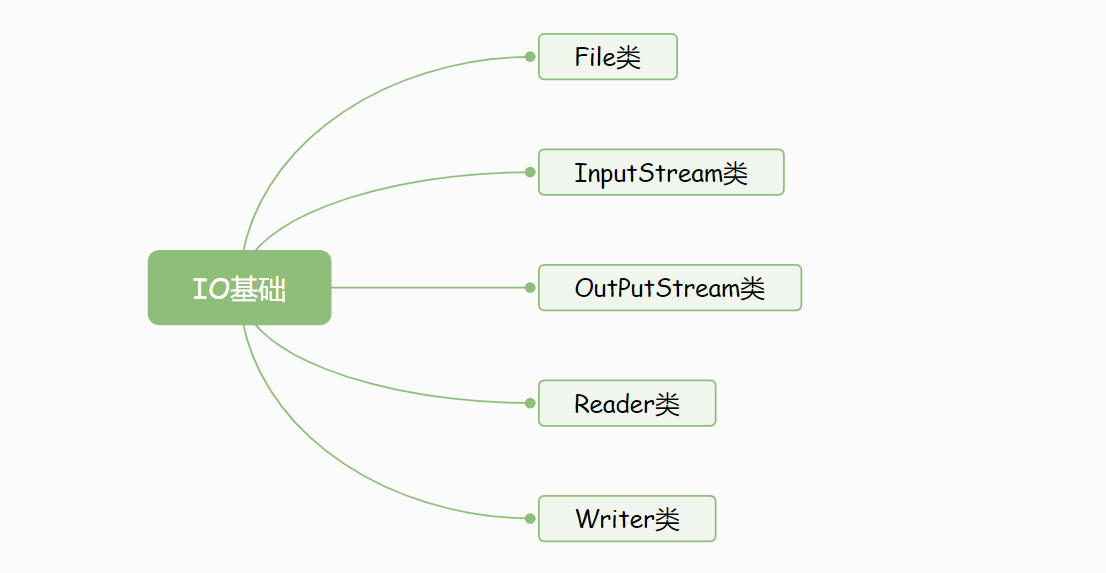
其中最为基础的是前三个:File类、InputStream类、OutputStream类,它们分别代表着文件、输入、输出。
举一个简单的例子:我把文件读取到java程序中,这里就是在输入,而我保存数据到文件中去,这里就是在输出。
下面两个类:Reader类、Writer类,同样是输入和输出,区别在于这两个传输的单位是字符,而前面那两个,传输的是字节。
File类
File者,文件也。
但是File类实际上可以表示两方面:文件、文件夹(目录)。
File类是一个盘古开天辟地时的类,从JDK1.0就存在了。最常见的实例化方式是把文件路径输入进去,就像这样:
1 | File file = new File("src/test.txt"); |
路径就是文件在计算机中的位置,有绝对路径和相对路径之分,比如这样:
1 | 绝对路径:"C:/JavaProgram/javaIO/src/test.txt" |
相对的意思就是,已经默认在某一个文件夹中了,前面那些路径就不用写了。
小总结一下:写清楚路径,通过路径拿到一个文件。
我认为对File类认识到这个地步就足够了。
InputStream类、OutputStream类
InputStream类、OutputStream类,这两个类是输入类和输出类,in是输入,out是输出,很明显。
这两个类也是盘古开天辟地时候的类,在JDK1.0就存在了。
(刚才忘了说,JDK是java开发的工具包,JDK1.0就是第一代开发工具包的意思,现在主流的开发包处在第7、8代,最新的已经到第12代了。)
我认为要了解清楚这两个类,需要搞清楚三件事情。
1. 传输的是什么东西?
上古类就该有上古类的样子,这两个类在输入输出时,传输的东西那都是最最最基本的单位:字节(就是1010……那串数字)。
因此InputStream的名字其实不是输入,而是字节输入流,OutputStream也不是输出,而是字节输出流。
2. 流是什么?
流(stream),这个概念基本就是java IO系统的核心了。
InputStream就是Input流,OutputStream就是Output流,想搞清楚这两个类是怎么工作的,最重要的就是理解“流”是什么。
我认为,“流”是一条中介管道,是连通java程序与外部存储的管道。它根本就没有流动,它是静态的,是装载着数据的一条中介管道。
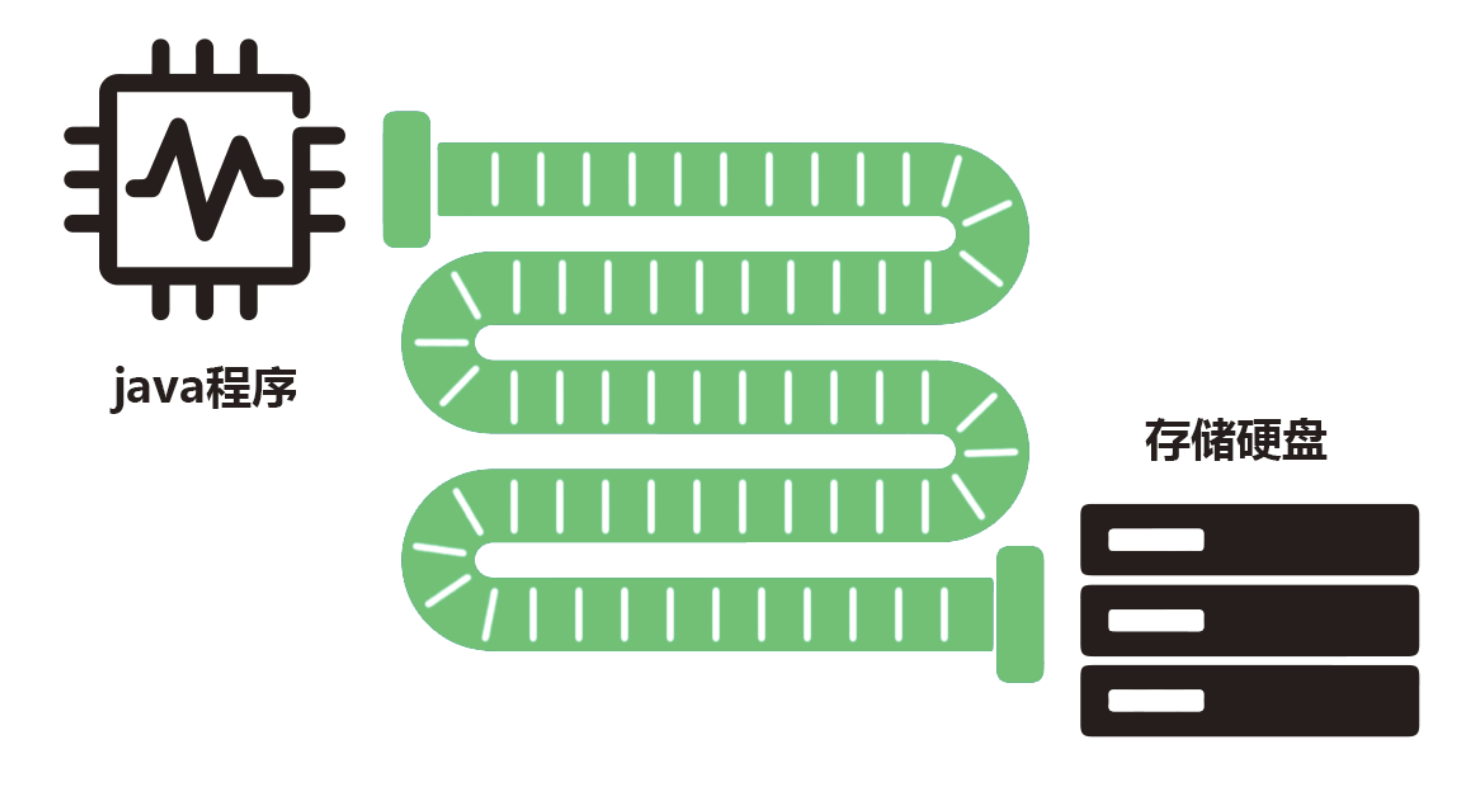
如图,我要把数据,从java程序传输到存储硬盘中,中途就会经过一条漫长的管道。这条管道有一个一个的小格子,每一个格子里面都放着一字节的数据。这整条管道,就叫做流。如果是一条输出管道,那就是输出流,如果是一条输入管道,那就是输入流。
我觉得“流”这个名字很具有迷惑性,让人感觉好像是数据在流动一样,但是我看了几天之后觉得并没有,这就是一条静态的、被分隔为很多很多小格子的,管道,每一个格子里面装着一字节的数据。(但是底层应该不是这么实现的,我是做等效看待了)
- 如果是输入流,那么把文件扔进管道,管道自动地将文件中的数据,按顺序一字节一字节地填充到管道的一个个小格子当中,每一格都是一字节的数据。数据并不会自动流过去,而是java程序自己顺着格子,拿走自己想要的数据。
- 如果是输出流,那么把java程序数据扔进管道,管道自动地将想要输出出去的数据,按顺序一字节一字节地填充到管道的一个个小格子当中,每一格都是一字节的数据。同样,数据也不会自动流到硬盘当中,而是有专门的函数,把这些数据顺着格子拷贝到硬盘里。
说了这么多虚的,该看看具体的代码了。
3. 这两个类怎么用?
我们用InputStream类入手,看一个简单的例子。
我现在写入两行代码,将文件放进输入流当中。
1 | File file = new File("src/test.txt"); |
这两行代码,可以理解为干了这么件事:
现在有一个txt文件,里面就写了一句英文,“Hello,pz.”,然后把这个文件扔进输入流中,输入流作为一条管道,分出了9个格子,每个格子放进去一个字母或是标点符号,就像是下面这张图一样。
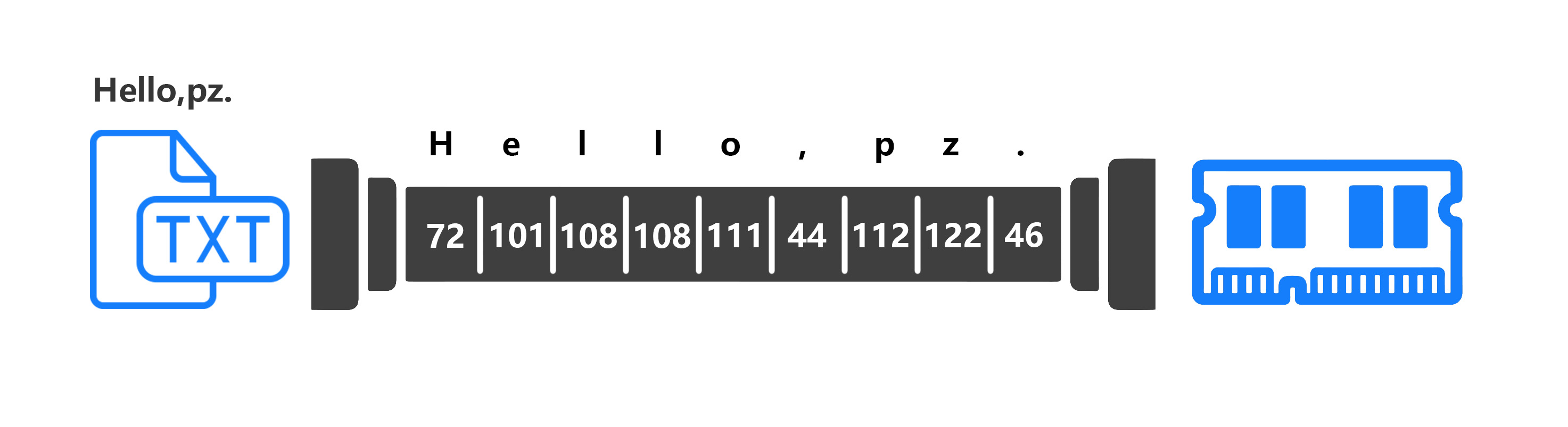
(数据是以010101……这种二进制数来表示的,比如字母H的二进制表示是01001000,转换成十进制后就是72,也就是上图管道中的第一个格子)
现在流已经存在了,要开始读取数据了。
InputStream类有一个方法read(),专门用来读取数据。但是由于java多态的特性,这一个read方法有三种使用方式。
1 | inputStream.read(); |
空参read()方法:
每次读一个格子的数据(读取一字节),并且返回这个数据。
1
2int i = -1;
i = inputStream.read();以上面两行代码为例,我首先声明了
i是一个整型数,然后去读取输入流的read()方法,第一次会读到72(字母H),然后如果你再执行一遍read()方法,就能读到下一个格子里的101(字母e),再执行一遍read()方法,就能读到108(字母l)……一直读到最后一个格子里的46(标点符号.),再读的话就没有东西了,就会返回-1。通过空参read()方法,能够每次读取一字节的数据,当读完时会返回-1。
1
2
3
4
5// 每次读取一个字节,然后在控制台打印出来这个字节,直到读空为止
int i = -1;
while ((i = inputStream.read()) != -1) {
System.out.print((char) i);
}参数是一个数组的read()方法:
每次读取数组长度的数据,返回读取的长度,同时把数据存放在数组中。
1
2
3int i = -1;
byte[] b = new byte[10];
i = inputStream.read(b);请注意,这里非常有迷惑性。
我们刚才使用的read()方法,用
i去读取,i里面直接存放数据。但是,我们现在把一个数组当做参数,扔进read()方法里,还是用
i去读取,但是现在i里面存放的,是读取的长度。比如说上面写的这三行代码,依旧是声明了
i是一个整型数,同时声明了b是一个长度为10的字节数组。现在我们去使用read()方法,i的值不再是72(字母H)了,而是9,因为输出流的长度是9(“Hello,pz.”一共九个字节),我们用一个长度是10的数组去读取它,一口气把这9个字节全读完了。现在数据不装在i里面了,而是直接装在数组b里面。也就是说,现在
i == 9,b == {72, 101, 108, 108, 111, 44, 112, 122, 46, 0},b这个数组,长度为10,前面9个全都存放着字节数据,最后一位没赋值所以是0。参数是一个数组、两个整型数的read()方法:
依旧是把数据放在数组里面,但是只用数组的一部分,返回值依旧是读取的长度。
1
2
3int i = -1;
byte[] b = new byte[10];
i = inputStream.read(b, 2, 5);跟第二种read()方法比,现在前两行的声明过程不变,第三行读取的时候,要求从数组
b的下标为2(因为第1个数下标是0,下标为2也就是第3个数)的地方开始存放数据,一直放5个数据。对比一下:
1
2i = inputStream.read(b); // b : {72, 101, 108, 108, 111, 44 , 112, 122, 46, 0}
i = inputStream.read(b, 2, 5); // b : {0, 0, 72, 101, 108, 108, 111, 0, 0, 0}
输入流,说完了。
(我知道我说得很烂,但是我不想重写了= =)
那么我们快速过一遍输出流。
OutputStream输出流同样输出的是字节,输出时用到的方法叫做write(),它同样有三种表现方式:
1 | outputStream.write(int b); // 一次写入一个字节 |
使用起来和输入流没什么区别,只不过一个是读取,一个是写入。
Reader类、Writer类
Reader类、Writer类,这两个类也是输入和输出类,read读,是输入,write写,是输出,也很明显。
这两个类不是盘古开天辟地时期的类,而是女娲造人时候的类,因为它们两个是JDK1.1出现的。
跟InputStream类、OutputStream类相比,区别在于,前面两个是输入输出字节,这两个是输入输出字符。
我们来谈一下字节和字符。
我认为可以这么理解,字节是计算机认识的文字,字符是人类认识的文字。比如计算机一看01001000这八个二进制数字,就知道这是一个字节,而我们人类一看到H,就知道这是一个字母(也就是一个字符)。
字节和字符之间,是存在着对应关系的(术语叫做映射),一个字符就应该对应着一个(或几个)字节,比如字符H,对应的就是01001000这8个二进制数所组成的一个字节。这种对应关系我们叫编码和解码,其实就是“翻译翻译”,字节 → 字符 :解码,字符 → 字节 :编码,也就是人话和机话互相翻译,要不然人类说一个字母H,计算机怎么存下来呢?
一个字节有8个二进制位,你算一算,2的8次方也就256,也就是说一个字节最多也就只有256种不同的情况,字符有数十万个,对应不过来啦,所以一个字符一般是对应两三个字节。(如果是英文,那一个字节256种情况倒也是够用了)
有许多不同标准的字符集,比如中国字字符集、英文字符集、欧洲字符集等等,我把相关信息列在表格中:
| 编码类型 | 解释 | 1个字符占几个字节 |
|---|---|---|
| ASCII | 最基础的字符集,有字母和符号等 | 1 |
| GBK | 中国字字符集(GB就是国标) | 中文字符占 2 个字节,英文字符占 1 个字节 |
| ISO-8859-1 | 大部分的欧美字符 | 1 |
| UTF-8 | Unicode编码的一种 最为常用,比如字符串转byte[]时就是 |
变长编码,1-6个字节都有 中文字符占 3 个字节,英文字符占 1 个字节 |
| UTF-16 | Unicode编码的一种 有UTF-16be和UTF-16le两种 be就是Big Endian(大端) le就是Little Endian(小端) |
变长编码(2或4),但是多数是2 java内存编码使用UTF-16be编码 因为char类型使用UTF-16be编码 中文字符和英文字符都占两个字节 |
我不打算写太多关于字符与字节的东西,只是简单记录一下。
好了我们说回输入输出。
- InputStream:字节输入流
- OutputStream:字节输出流
- Reader:字符输入流
- Writer:字符输出流
InputStream类、OutputStream类输入输出的是byte。
Reader类、Writer类输入输出的是char。
就这点区别,没啥别的了。
好吧我们还是惯例看看使用的方法:
Reader类的read()方法
1
2
3
4reader.read();
reader.read(char[] cbuf);
reader.read(char[] cbuf, int off, int len);
reader.read(CharBuffer target);Writer类的write()方法:
1
2
3
4
5writer.write();
writer.write(char[] cbuf);
writer.write(char[] cbuf, int off, int len);
writer.write(String str);
writer.write(String str, int off, int len);
好吧,看起来多了几个方法。
但说实话,我觉得本质上没什么区别,无非就是又包装了一下,用起来更顺手一些。流的使用上,是没有区别的。
所以这两个类,我们就不再说了。
让我们重看一遍一开始的那张图,这五个最为基础的类,可以再分成三类,一类跟文件打交道,一类跟字节打交道,一类跟字符打交道。
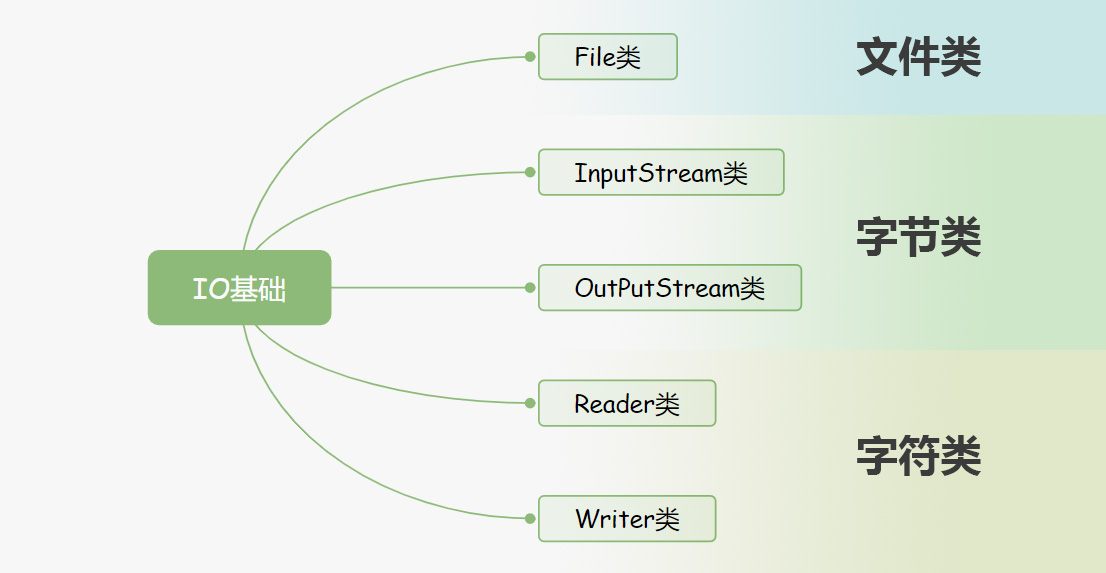
在表述逻辑无比混乱地写完java IO基础的五个类之后,我们来学习装饰者模式。(啊真的想重写,可是又没力气)
装饰者模式
装饰者模式是这样的,我现在有一个类,但是我发现这个类的功能有限,我想给这个类增加几个功能,那么我就在这个类的外面,再套上一层,这么包装完之后呢,这个“被装饰过”的类,不单具有原先的功能,还有了一些新的功能。
装饰者模式的主要动作就是,有了一个类,给它套上一层装饰,变成了一个新的类,这个类增加了功能。
我们拿字节输入流举例子。
我们在使用InputStream类时,java程序是一字节一字节地读取数据的,这一个个读,其实是很慢的。如果java程序能加一层缓存,每一次多读一点数据,就会快一些。
我们现在希望实现的功能是:在原先InputStream类的基础之上,增加一个缓存的功能,因此我们是这么实现的:
1 | InputStream is = new FileInputStream(file); |
首先还是先实例化了一个InputStream对象is,接着我们装饰了这个is,让它变成一个BufferedInputStream对象bs(就是一个buffer过的InputStream)。那么现在,我们不再去操作is,而是去操作bs了,bs是一个具有缓存功能的is,是一个更强大的is。
(BufferedInputStream类具体强大在哪里呢?它也没多加什么新方法,它就是运行速度更快,快很多很多,读大文件的时候很明显。)
java IO系统中,装饰者模式比比皆是,全都是拿到一个输入/输出类,然后装饰一下变成一个新的类,去操作这个新的类,去实现更多的功能。
装饰者模式是一种设计模式,它的好处在于,如果我想给某些类实现一个新的功能,可以不通过继承,而是通过一个中间类去装饰一下即可。
比如现在有一个运动类,运动类下面有很多子类:跑步类、打球类、跳绳类……我现在希望每一个运动类的子类,这么多类,都去实现运动完之后拉伸的方法。按照原来的思路,我要把所有子类全部都继承一遍,每一个新继承的类都多加上这么一个运动完之后拉伸的方法,那不是累死了吗。通过装饰者模式,我可以创建一个运动后拉伸类,这个类读取一个运动类,随便哪个子类都可以,在这一装饰之下,就新增了拉伸的方法。这样做动静很小。
java IO系统这么青睐装饰者模式,主要是也是因为,特喵的java的IO相关类,实在是太多了……